Capítulo 15 Loops
15.1 Introdução
Os loop’s são uma outra categoria de controles de fluxo que praticamente toda linguagem de programação oferece. Portanto, eles impactam a ordem em que certos comandos são avaliados pelo R. Sendo mais preciso, um loop te permite executar múltiplas vezes um mesmo conjunto de comandos, criando assim, um “espaço de repetição” no fluxo de execução de seu programa.
Loop’s são particularmente úteis, quando desejamos replicar uma mesma função (ou um mesmo conjunto de comandos) sobre vários inputs diferentes. Loop’s também são parte essencial quando desejamos trabalhar com listas (list), seja caminhando por ela (isto é, visitando cada um de seus elementos), ou modificando-a de uma forma simples e automatizada.
15.2 O que são loops ?
Um loop te permite executar repetidas vezes um mesmo conjunto de comandos, e, assim como ocorre em outras linguagens, nós temos diferentes “tipos” de loops no R. Mais especificamente, a linguagem oferece três tipos explícitos de loop que são: 1) for loop; 2) while loop; 3) repeat loop. Além disso, a linguagem também oferece as palavras-chave next e break, que oferecem maior controle sobre a execução de loops (TEAM, 2020a). Também temos tipos implícitos de loop oferecidos pela família de funções apply (apply(), tapply(), sapply(), vapply(), e lapply()). Entretanto, vamos focar por enquanto neste capítulo nos tipos explícitos de loop.
A diferença entre cada tipo de loop, está apenas em como eles determinam o número de repetições que eles vão executar, ou em como eles decidem parar essa repetição. O tipo mais simples de todos é provavelmente o while loop, que em resumo, vai repetir um certo conjunto de comandos, enquanto uma certa condição lógica resultar em TRUE. Por outro lado, o tipo mais genérico de todos é o for loop, que vai repetir os comandos de acordo com um “índice de repetição”. E o tipo menos comum de todos é o repeat loop, que vai repetir o conjunto de comandos indefinidamente, até que uma condição de break seja executada.
O exemplo mais simples de um loop, provavelmente seria um for loop que simplesmente nos mostra o valor que o seu iterador assume a cada repetição. Tal exemplo está reproduzido abaixo. Perceba que a cada repetição do for loop, ele está executando o comando print(i). Descrevendo de outra forma, a cada repetição do for loop, a função print() é executada, a qual procura por um objeto chamado i, e nos retorna como resultado, o conteúdo desse objeto. No exemplo abaixo, esse objeto i é o “iterador” do for loop. Esse iterador é um objeto que guarda o índice de repetição do loop.
for(i in 1:5){
print(i)
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
15.3 Descrevendo um for loop
Um for loop é sempre iniciado pela palavra-chave for, seguido por um par de parênteses, onde é feita a “definição do loop”, e, depois, por um par de chaves, onde é incluído o “corpo do loop”, ou o conjunto de comandos que vão ser executados em cada repetição. Portanto, todo for loop possui esses dois componentes: definição e corpo. Todo while loop também possui essas duas partes, contudo, um repeat loop possui apenas o corpo. Para uma noção mais clara, eu delimitei cada componente na figura 15.1.

Figura 15.1: Componentes de um for loop
15.3.1 Definição
A definição de um for loop é formada dentro de um par de parênteses, logo após a palavra-chave for. Dentro desse par de parênteses, temos três itens diferentes: 1) um iterador, ou, um “índice de iteração”; 2) a palavra-chave in; e 3) um objeto qualquer (geralmente um vetor). Essa definição deve sempre conter esses três itens.
Um iterador é um objeto (ou uma variável) que será reservado para conter o índice do loop. Em outras palavras, o iterador é um objeto criado pelo for loop, que será responsável por armazenar o índice de repetição do loop. A cada repetição, o iterador de um for loop vai assumir um valor diferente. Mais especificamente, ele vai armazenar um elemento diferente do objeto que você forneceu após a palavra-chave in.
Ou seja, esse objeto (ou o “terceiro item” da definição) que você forneceu determina o conjunto de valores que o iterador vai assumir ao longo da execução do for loop. Por exemplo, se eu forneço o vetor 1:5, significa que o iterador vai assumir os valores 1, 2, 3, 4 e 5 ao longo da execução do loop. Mas se eu forneço o vetor c("Ana", "Eduardo", "Márcia"), então esse iterador vai assumir os valores "Ana", "Eduardo" e "Márcia" a medida em que o loop realiza suas repetições.
Portanto, na 1° repetição do loop, o iterador vai conter o 1° elemento do objeto que você forneceu após a palavra-chave in, já na 2° repetição, o iterador vai conter o 2° elemento, e assim por diante. O que será cada um desses elementos, vai depender do objeto que você forneceu e da estrutura de dados que ele utiliza. Perceba no exemplo abaixo, que o iterador i assume o valor "a" na 1° repetição do loop, depois, o valor "b" na 2° repetição, e depois, o valor "c" na 3° e última repetição do loop.
## [1] "a"
## [1] "b"
## [1] "c"Repare também pelo exemplo acima, que o tamanho (ou o número de elementos) do objeto que você forneceu, determina o número de repetições que o for loop vai executar. Desse modo, se um while loop utiliza uma condição lógica para determinar o número de iterações a serem executadas, um for loop se baseia apenas no número de elementos presentes no objeto que você estabeleceu na definição do loop. Logo, se você utiliza, por exemplo, um data.frame de 5 colunas, o for loop vai repetir os comandos 5 vezes, mas se você utiliza uma lista de 30 elementos, então o for loop vai iterar 30 vezes sobre os comandos definidos em seu corpo.
Ainda observando o exemplo acima, ao invés de fornecermos um vetor de character’s, é mais comum fornecermos um vetor contendo uma sequência de integer’s, utilizando o operador : (como 1:10) ou funções de sequência como seq_along() e seq_len(). Dessa forma, o iterador se comporta como um índice numérico, que representa o número da repetição em que o loop se encontra. Dito de outra forma, se o meu loop está na 1° repetição, o iterador vai conter o valor 1, se o loop está na 2° repetição, o iterador passa a conter o valor 2, e assim por diante.
Portanto, eu poderia muito bem reescrever o loop anterior, utilizando dessa vez um índice numérico para acessar os elementos do vetor letras. Repare abaixo, que estou utilizando o índice numérico do iterador em conjunto com subsetting, para acessar cada elemento do vetor letras.
## [1] "a"
## [1] "b"
## [1] "c"Perceba também no exemplo acima, que estou aplicando a função seq_along() sobre o vetor letras. Tudo que essa função faz, é me retornar uma sequência de 1 até o número de elementos contidos no objeto em que apliquei ela. Logo, o resultado de seq_along() no caso acima, é um vetor contendo uma sequência de 1 a 3. Isso também significa que, eu poderia muito bem substituir essa expressão seq_along(letras) por 1:3, ou, c(1, 2, 3), ou, 1:length(letras).
A função seq_len() é irmã de seq_along(). Essa função gera uma sequência de 1 até o número que você oferecer à função. Ou seja, a expressão seq_len(3) é equivalente a 1:3, e seq_len(100), à 1:100, e assim por diante. Tendo isso em mente, poderíamos reescrever o loop acima da seguinte maneira:
## [1] "a"
## [1] "b"
## [1] "c"Caso o resultado da expressão length(letras) fosse igual a zero, as funções seq_along() e seq_len() nos retornaria um vetor do tipo integer de comprimento zero. Dessa forma, o for loop não é executado pelo R. Ou seja, como o vetor em questão estaria vazio, o iterador do for loop não teria nenhum elemento para iterar sobre.
Uma expressão como 1:length(x) funciona perfeitamente bem quando o vetor x possui comprimento maior que 1. Todavia, quando esse vetor possui comprimento zero, a expressão 1:length(x) acaba nos retornando 1:0 (isto é, o vetor c(1, 0)) como resultado, ao invés de um vetor vazio. Um detalhe como esse, pode causar erros no mínimo medonhos e de difícil rastreabilidade quando utilizamos esse vetor em um for loop. Ao evidenciar essa diferença, quero destacar que as funções seq_along() e seq_len() são métodos mais seguros e apropriados de se criar essas sequências a serem utilizadas pelo iterador de um for loop.
Para mais, vale destacar que, o objeto definido após a palavra-chave in pode ser qualquer coisa que a linguagem te permite definir. Geralmente esse objeto é um vetor de índices numéricos, como nos exemplos acima, mas ele poderia muito bem ser uma lista ou um data.frame, ou algo mais de sua preferência. Qualquer que seja a sua escolha, o for loop vai caminhar ao longo desse objeto que você forneceu, elemento por elemento.
Por uma convenção, programadores em geral, quase sempre utilizam a letra i para representar esse iterador. Especialmente se se esse iterador contém um índice numérico. Mas você tem a liberdade de dar o nome que quiser para o seu iterador. Como exemplo, eu poderia muito bem criar um iterador chamado fruta.
## [1] "Banana"
## [1] "Maçã"
## [1] "Pêra"
## [1] "Pêssego"
## [1] "Laranja"O iterador é parte essencial de um for loop, pois em geral, utilizamos esse iterador para acessarmos um elemento diferente de algum objeto, ou, para gerarmos um resultado diferente a cada repetição do loop. Veja no exemplo abaixo, que a cada iteração o for loop está somando 10 a um elemento diferente do vetor valores. Consequentemente, o valor armazenado no objeto soma muda a cada repetição do for loop.
## [1] 25
## [1] 30
## [1] 35
## [1] 40Portanto, geralmente utilizamos o iterador para aplicarmos uma função sobre um input diferente e, com isso, gerar um resultado distinto a cada repetição. Esse input pode ser o próprio índice numérico do iterador (como nos exemplos em que aplicamos a função print() sobre o iterador), ou, então, um elemento (ou parte) de algum objeto (como no exemplo acima, do vetor valores).
Contudo, temos também a opção de não utilizamos o iterador ao longo do corpo do loop. Dessa forma, o loop vai sempre executar os mesmos comandos, que por sua vez, vão utilizar sempre os mesmos inputs e, consequentemente, vão gerar sempre o mesmo resultado a cada repetição.
## [1] "Essa soma é igual a: 25"
## [1] "Essa soma é igual a: 25"
## [1] "Essa soma é igual a: 25"
## [1] "Essa soma é igual a: 25"
## [1] "Essa soma é igual a: 25"15.3.2 Corpo
O corpo de um for loop (assim como de qualquer outro tipo de loop) contém o conjunto de comandos que serão executados a cada repetição. Dessa maneira, você deve inserir dentro desse corpo, todos os comandos que você deseja que esse for loop execute por você. Nesse sentido, o corpo de um loop funciona de uma maneira muito parecida com o corpo de uma função.
Como exemplo, eu posso utilizar um for loop para realizar 5 jogadas de um dado tradicional. Dessa forma, em cada uma das 5 repetições, o for loop executa a função sample() para sortear um número de 1 a 6, e, em seguida, me mostra qual foi o número sorteado através da função print().
## [1] 1
## [1] 6
## [1] 5
## [1] 4
## [1] 215.4 Armazenando os resultados de um loop.
O que acontece dentro de um loop (seja ele um for, while ou repeat loop) permanece dentro desse loop (GROLEMUND, 2014). Isso significa que os resultados gerados ao longo da execução de um loop não são salvos, a menos que você peça explicitamente por isso.
Imagine por exemplo, que você deseja simular 20 jogadas do dado, utilizando um loop como o da seção anterior. Porém você deseja ter os números sorteados em cada jogada, salvos em algum objeto, para que você possa fazer cálculos sobre esses resultados após a execução do loop. Para isso, você precisa utilizar uma expressão de assignment para salvar (em algum objeto) um resultado gerado dentro de seu loop.
No exemplo abaixo, eu estou criando um vetor do tipo integer com 20 elementos chamado jogadas. Em seguida, dentro do loop, eu estou usando o operador de assignment (<-) para salvar o resultado de cada jogada em um dos elementos do vetor jogadas. Como resultado, se quisermos utilizar os números sorteados ao longo do loop em algum cálculo posterior, basta utilizarmos o objeto jogadas.
## [1] 5 1 2 2 5 5 3 4 5 4 4 1 6 6 5 4 1 1 2 5Perceba no exemplo acima, que eu reservei o espaço para cada resultado antes do for loop. É muito importante que você crie previamente, um objeto que possa guardar os resultados de seu loop (GROLEMUND, 2014; WICKHAM; GROLEMUND, 2017). Logo, esse objeto precisa ter espaço suficiente para comportar todos os resultados gerados pelo seu loop.
Por exemplo, se eu possuo um data.frame contendo 4 colunas numéricas, e desejo calcular a média de cada coluna, eu preciso criar algum objeto que possa receber as 4 médias que serão geradas pelo loop. No exemplo abaixo, eu utilizo a função vector() para criar um novo vetor atômico chamado media. Este vetor é do tipo double, e possui 4 elementos. Sendo assim, dentro do corpo do loop, eu salvo os resultados da função mean() dentro de cada elemento do vetor media.
df <- data.frame(
a = rnorm(20),
b = rnorm(20),
c = rnorm(20),
d = rnorm(20)
)
media <- vector(mode = "double", length = 4)
for(i in 1:4){
media[i] <- mean(df[[i]])
}
media## [1] -0.0260228 0.1182790 0.1210387 0.3298290Por que é muito importante que você reserve o espaço para cada resultado antes do loop? Pois caso contrário, o nosso loop pode ficar muito lento, dado que, para cada resultado gerado, o R precisa reservar um tempo durante a execução, para expandir o objeto em que você está salvando esses resultados (GROLEMUND, 2014).
Em mais detalhes, se você possui um vetor x de 5 elementos, e adiciona um 6° elemento a ele, para que o vetor “cresça”, o R é obrigado a criar um novo vetor de 6 elementos em um outro endereço de sua memória RAM, e copiar todos os 5 elementos do vetor x para esse novo endereço, e, por fim, adicionar o 6° elemento a este novo vetor criado. Obviamente esse processo é feito de maneira automática, mas com certeza é um processo altamente custoso.
Dentro da comunidade do R, esse problema é mais conhecido pelo termo growing vector problem (ou “problema do vetor crescente”). Caso estivéssemos usando um loop de 2 mil repetições, o R precisaria executar 2 mil vezes o processo descrito no parágrafo anterior, para aumentar um elemento a mais em meu vetor, com o objetivo de guardar o novo resultado gerado em cada uma dessas 2 mil repetições. Por outro lado, se eu já reservo previamente um vetor com 2 mil elementos, o R não precisaria mais executar esse processo, e pode se dedicar apenas na execução do loop.
Como exemplo, eu realizei um pequeno teste em minha máquina. Em ambos os exemplos abaixo estou realizando o mesmo loop de 10 milhões de repetições. A cada repetição, esse loop salva o valor do iterador em um vetor chamado vec. A diferença entre os dois exemplos, é que no primeiro eu expando o vetor vec a cada repetição e, no segundo, o vetor vec já possui 10 milhões de elementos antes do loop começar. Repare abaixo, que a minha máquina demorou em torno de 3,92 segundos para executar o primeiro exemplo, mas apenas 0,43 segundos para executar o segundo.
system.time({
vec <- 0
for(i in 1:10000000){
vec[i] <- i
}
})## usuário sistema decorrido
## 3.47 0.41 3.92
system.time({
vec <- vector("integer", length = 10000000)
for(i in 1:10000000){
vec[i] <- i
}
})## usuário sistema decorrido
## 0.40 0.02 0.43Além disso, é muito importante que você crie um vetor associado ao mesmo tipo de dado que o resultado gerado em seu loop. Logo, se o seu loop gera um valor do tipo double em cada repetição, é importante que você crie um vetor do tipo double para armazenar esses resultados. Também é essencial que você saiba o tamanho que esse resultado pode assumir em cada repetição. Em outras palavras, será que a cada repetição de seu loop, um único número é gerado (por exemplo, uma média)? Ou um novo vetor de 5 elementos? Ou um data.frame de tamanho variável?
A partir do momento que você sabe qual o tipo de resultado que será gerado pelo seu loop, você pode identificar com mais facilidade, qual a melhor estrutura de dado para guardar esses valores. Pergunte-se: será que um vetor atômico consegue guardar esses resultados? Ou uma lista é mais adequada? Lembre-se que vetores atômicos só podem guardar dentro de si, valores que pertencem ao mesmo tipo de dado (double, integer, logical, character, etc.). Além disso, nós não podemos guardar um novo vetor ou um novo data.frame, dentro de cada elemento de um vetor atômico. Logo, se a cada repetição do loop você está gerando um vetor, uma lista ou um data.frame, é melhor que você utilize uma lista para armazenar cada um desses resultados (ao invés de um vetor atômico).
Para criar uma nova lista de \(n\) elementos, você pode utilizar novamente a função vector(). Basta que você configure o argumento mode da função para o valor "list". Lembre-se que, para acessar um elemento de uma lista, você precisa utilizar 2 pares de colchetes ao invés de 1 par. No exemplo abaixo, estou utilizando um for loop para realizar um trabalho semelhante à função split(), que é o de dividir (ou separar) as linhas de um data.frame em diferentes elementos de uma lista, de acordo com os valores de uma determinada coluna.
tab <- data.frame(
setor = c("B", "C", "C", "A"),
ID = c("1154", "678", "9812", "2500"),
valor = round(rnorm(4), 2)
)
setores <- c("A", "B", "C")
lista_vazia <- vector("list", length = 3)
names(lista_vazia) <- setores
for(setor_id in setores){
lista_vazia[[setor_id]] <- filter(tab, setor == setor_id)
}
lista_vazia## $A
## setor ID valor
## 1 A 2500 -1.23
##
## $B
## setor ID valor
## 1 B 1154 -1.1
##
## $C
## setor ID valor
## 1 C 678 1.42
## 2 C 9812 -1.6115.4.1 Alguns outros padrões de loops
Loops são ferramenta fundamental para trabalharmos com listas no R. Pois a linguagem não trata as listas da mesma forma que os vetores atômicos. Logo, operações muito simples e corriqueiras, como aplicar uma determinada operação sobre todos os elementos de um vetor, não possuem a mesma solução direta quando lidamos com uma lista. Por exemplo, se eu tentasse multiplicar cada elemento de uma lista por 2, da mesma forma que eu faria para um vetor atômico, um erro é retornado:
list(1, 2, 3) * 2## Error in list(1, 2, 3) * 2 : argumento não-numérico para operador binárioAplicar uma determinada operação/função sobre cada elemento de uma lista é uma atividade bastante comum no R. Porém, para realizarmos esse trabalho, temos que utilizar um loop para navegar sobre cada elemento dessa lista, aplicando a operação/função que desejamos aplicar. Nesse aspecto, uma lista da linguagem R se aproxima muito à uma lista da linguagem Python, que também exige o uso de loops para trabalharmos com cada elemento.
Como exemplo, para multiplicarmos cada elemento de uma lista por 2, teríamos que construir um loop parecido com este. Nesse exemplo, estou utilizando o iterador do loop para acessar cada elemento da lista, através do comando lista[[i]] e, em seguida, estou multiplicando esse elemento por 2 e, por último, salvo o resultado nesse mesmo elemento da lista.
## [[1]]
## [1] 2
##
## [[2]]
## [1] 4
##
## [[3]]
## [1] 6Além disso, até o momento, focamos bastante em loops que utilizam vetores contendo uma sequência numérica. Contudo, também é muito comum iterarmos sobre vetores contendo nomes (ou rótulos), com o objetivo de extrairmos ou modificarmos elementos específicos de uma lista, ou, colunas específicas de um data.frame. Por exemplo, imagine que você possua um data.frame parecido com o objeto tab abaixo.
tab <- data.frame(
ID = c("A", "A", "B", "C"),
c1 = rnorm(4),
c2 = rnorm(4),
c3 = rnorm(4)
)Agora, suponha que você desejasse calcular a média de todas as colunas numéricas dessa tabela. Para isso, você poderia utilizar um código parecido com esse:
Entretanto, essa solução se torna rapidamente inviável a medida em que o número de colunas numéricas em seu data.frame aumenta. Logo, uma solução mais interessante, seria primeiro, coletarmos o nome das colunas que são numéricas e, em seguida, utilizar um loop para iterarmos ao longo dessas colunas, calculando a média de cada uma.
Para coletarmos os nomes das colunas numéricas, poderíamos construir um loop como o demonstrado abaixo. Dessa forma, estamos empregando a função is.numeric() sobre cada coluna de tab, e armazenando o resultado no vetor vec. Ao final do loop, o vetor vec guarda um valor do tipo logical para cada coluna de tab, indicando se essa coluna é numérica ou não. Com isso, podemos utilizar esse vetor vec com subsetting sobre o resultado da função names(), para descobrirmos os nomes das colunas numéricas de tab.
vec <- vector("logical", length = ncol(tab))
for(i in seq_along(tab)){
vec[i] <- is.numeric(tab[[i]])
}
colunas_numericas <- names(tab)[vec]
colunas_numericas## [1] "c1" "c2" "c3"Com esses nomes guardados, podemos construir um novo loop que utiliza esses nomes para acessar cada uma dessas colunas numéricas de tab, e aplicar a função mean() sobre cada uma delas. Como resultado, temos um novo vetor chamado medias que contém as médias de cada coluna numérica de tab.
medias <- vector("double", length = length(colunas_numericas))
for(i in seq_along(colunas_numericas)){
coluna <- colunas_numericas[i]
medias[i] <- mean(tab[[coluna]])
}
names(medias) <- colunas_numericas
medias## c1 c2 c3
## -0.6090414 0.3384576 0.5603875Portanto, no exemplo acima, a coluna ID do objeto tab não foi acessada em momento algum pelo for loop. Pois o nome dessa coluna não está presente no vetor colunas_numericas. Sendo assim, quando estamos trabalhando com estruturas nomeadas (como listas e data.frame’s), podemos utilizar um for loop em conjunto com o nome atribuído a cada elemento dessa estrutura para acessar e modificar elementos específicos do objeto, sem afetarmos os demais elementos do mesmo.
15.4.2 Cuidado com o nome de seu iterador
O iterador é uma variável criada automaticamente pelo for loop. Porém, tome muito cuidado, pois a depender do ambiente em que o for loop for executado, essa variável pode ser criada em seu ambiente global (global environment). Isso significa que, o iterador criado pelo for loop pode acabar sobrescrevendo um objeto que você criou anteriormente em seu ambiente.
Por isso, mesmo que você tenha liberdade para definir o nome que desejar para o seu iterador, é importante que você tome cuidado para não sobrescrever algum objeto importante durante o seu programa. Apenas para que esse problema fique claro, veja no exemplo abaixo, que eu crio antes do loop, um objeto i que guarda o texto "Uma anotação importante". Após o loop, eu verifico o que está armazenado nesse objeto i, e o número 3 é retornado (ao invés da anotação importante).
i <- "Uma anotação importante"
for(i in 1:3){
soma <- 15 + 3
}
print(i)## [1] 3No exemplo acima, como o iterador do loop se chamava i, o for loop cria um novo objeto chamado i, o qual sobrescreve o objeto i anterior que guardava a string. Após a execução do loop, este objeto i guarda o número 3, que é o valor que esse iterador assumiu na última repetição do for loop.
Portanto, o iterador de um for loop, é um objeto criado no ambiente (ou environment) em que esse for loop é chamado. Uma solução inteligente para esse problema gerado pelo for loop, seria executarmos esse loop através de uma função. Pois, como discutimos no capítulo anterior, as funções são executadas em ambientes separados do seu ambiente global. Dessa forma, o iterador do for loop é criado no ambiente em que essa função é executada. Perceba abaixo, que dessa vez, mesmo após executarmos a função contendo o loop, o objeto i ainda contém a anotação importante.
i <- "Uma anotação importante"
f <- function(){
for(i in 1:3){
soma <- 15 + 3
}
}
### Executei a função
f()
### O valor do objeto i continua o mesmo
print(i)## [1] "Uma anotação importante"
15.5 Descrevendo um while loop
Um while loop é criado a partir da palavra-chave while. Assim como um for loop, um while loop também possui uma definição e um corpo. Sendo que o seu corpo funciona exatamente da mesma forma que em um for loop. Logo, você inclui dentro do corpo de um while loop, os comandos a serem executados em cada iteração.
Porém, a definição de um while loop é construída de uma forma diferente. Essa definição também é construída dentro de um par de parênteses, logo após a palavra-chave while, contudo, ela possui 1 único item dentro dela, que é a condição lógica responsável por reger (ou coordenar) o loop. No exemplo abaixo, essa condição lógica é i < 5.
Repare também, que eu crio o objeto i antes do while loop ocorrer. Logo, ao contrário de um for loop, um while loop não utiliza um iterador, ou, em outras palavras, um while loop não cria um objeto durante sua execução, ele apenas confere o resultado da condição lógica i < 5 a cada repetição.
i <- 1
while(i < 5){
print(i)
i <- i + 1
}## [1] 1
## [1] 2
## [1] 3
## [1] 4Portanto, a cada repetição, o while loop confere se o resultado de i < 5 é igual a TRUE, caso seja, os comandos definidos no corpo desse loop são executados. Perceba que, no exemplo acima, o loop nos mostra o conteúdo do objeto i com print() e, em seguida, acrescenta 1 ao valor do objeto i com i <- i + 1. Como esse incremento é executado em toda repetição do loop, em algum momento, o valor de i será maior ou igual a 5 e, consequentemente, o resultado da condição lógica i < 5 não será mais TRUE. No instante em que essa condição retornar FALSE, o while loop vai encerrar sua execução. Esse fluxo de execução está desenhado na figura 15.2 abaixo.
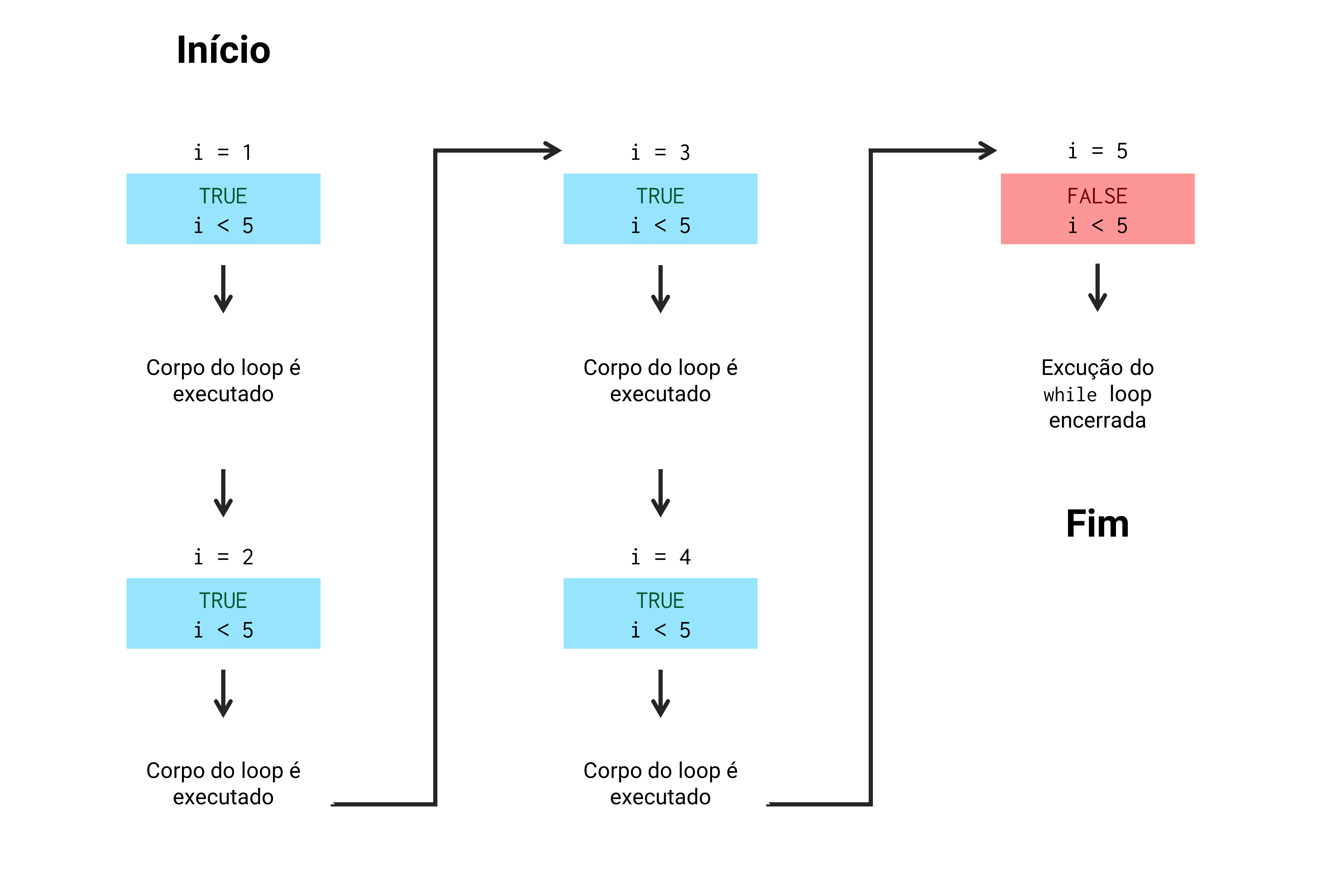
Figura 15.2: Fluxo de execução de um while loop
Tendo isso em mente, um while loop repete um mesmo conjunto de comandos enquanto uma condição lógica for verdadeira (GROLEMUND, 2014). Agora, tenha cuidado com um while loop, pois se a condição que rege o loop nunca resultar em FALSE, o loop nunca vai encerrar a sua execução. Ou seja, podemos criar um loop infinito.
Se você decidiu utilizar um while loop (ao invés de um for loop), é razoável pressupormos que os comandos inseridos no corpo deste loop vão decidir se essa condição vai continuar resultando em TRUE ou não. Logo, se o código presente no corpo de seu while loop não possui qualquer relação com a condição lógica que você forneceu na definição do loop, esse loop nunca vai parar de repetir os comandos descritos em seu corpo (GROLEMUND, 2014).
No exemplo anterior, o comando i <- i + 1 presente no corpo do loop, gerava um “crescimento” do objeto i a cada iteração e, por causa disso, garantia que em algum momento, a condição i < 5 resultaria em FALSE. Mas o que seria um caso de while loop infinito ? Um exemplo seria um loop que utiliza uma condição formada por constantes, como 1 < 5. Pois 1 sempre será menor que 5, logo, essa condição sempre resultará em TRUE. Um outro exemplo seria o loop abaixo, que utiliza uma condição lógica em torno do objeto x, mas que não possui nenhum comando presente em seu corpo, que altere esse objeto x de alguma forma que possa tornar a condição lógica x == 10 igual a FALSE.
x <- 10
contagem <- 1
### Esse loop é infinito:
while(x == 10){
print(contagem)
contagem <- contagem + 1
}Entenda que, a definição de um while loop pode conter qualquer tipo de condição lógica que você quiser. Você pode inclusive fornecer diretamente um valor do tipo logical a essa definição (apesar de que isso criaria um loop infinito - TRUE, ou, um loop que jamais executaria os comandos de seu corpo - FALSE). De qualquer forma, a condição lógica que você fornecer à definição de um while loop, deve resultar em 1 único valor do tipo logical. Caso essa condição resulte em um vetor de valores do tipo logical, while vai utilizar apenas o primeiro elemento deste vetor para determinar se o loop prossegue ou não com a sua iteração.
15.6 Descrevendo um repeat loop
Um repeat loop é um loop infinito por definição. Logo, você precisa ter um cuidado em dobro com este tipo de loop. Sendo assim, um repeat loop vai repetir indefinidamente o conjunto de comandos descritos no corpo do loop. Por esse motivo, quando utilizamos um repeat loop, nós geralmente criamos uma condição de break em seu corpo.
Em resumo, o comando break cria uma ordem que interrompe o loop que o executou. Portanto, break é uma palavra-chave que deve ser utilizada dentro do corpo de qualquer tipo de loop. Com essa palavra-chave, podemos transformar um loop infinito, em um loop finito. Como exemplo, podemos recriar o exemplo básico de loop com um repeat loop dessa forma:
i <- 1
repeat{
if(i >= 5){
break
}
print(i)
i <- i + 1
}## [1] 1
## [1] 2
## [1] 3
## [1] 4Perceba acima, que um repeat loop não possui uma definição, apenas o corpo. Em um for loop ou while loop, a definição determina o momento em que a iteração do loop deve ser finalizada. Como um repeat loop é um loop infinito, não faz sentido criarmos uma definição para ele.
Em vista disso, assim como ocorre em um while loop, você também precisa incluir dentro do corpo de um repeat loop, comandos que possam decidir quando é o momento de parar o loop, dessa vez, utilizando um comando break. No exemplo acima, utilizo um if statement dentro do corpo do loop para fazer essa decisão.
15.7 Pulando repetições com next
Enquanto break para a execução de um loop, next faz com que o loop vá direto para a próxima iteração. Dito de outra forma, a palavra-chave next no R é equivalente à palavra-chave continue nas linguagens C e Python.
Como exemplo, o loop abaixo utiliza um if statement com o teste lógico i %% 2 == 0 para verificar se o valor do objeto i é um número par, caso seja, o loop vai executar um comando next para pular os comandos restantes do corpo do loop, e ir direto para a próxima iteração. Em outras palavras, quando o iterador i assume valores pares, como 2 e 4, o loop não chega a executar o comando print(i), pois o comando next já moveu o loop para a próxima repetição.
## [1] 1
## [1] 3
## [1] 515.8 Um estudo de caso: exportando múltiplas planilhas de Excel
O pacote readxl (que introduzimos no capítulo 4) nos oferece a função read_excel(), com a qual podemos ler (ou importar) planilhas do Excel no R. Porém, o pacote não nos oferece uma função capaz de escrever (ou exportar) um data.frame do R para um arquivo de Excel.
Apesar do R não oferecer de fábrica uma solução, existem vários outros pacotes disponíveis que trabalham com planilhas de Excel, e que oferecem funções capazes de escrever tal formato de arquivo. Sendo os principais: openxlsx, xlsx e writexl.
O pacote writexl é o mais recente e simples de todos dessa lista, dado que ele oferece uma única função, chamada write_xlsx(). Entretanto, isso também significa que ele é a opção mais limitada, e não oferece várias funcionalidades importantes (por exemplo, a adição de abas, ou sheets, ao arquivo). Este pacote é uma interface para a biblioteca libxlsxwriter (escrita em C). Por causa disso, writexl é, em geral, o pacote que escreve os menores arquivos (em tamanho) e no menor tempo possível. Tendo isso em mente, se você precisa de uma solução simples e performática, writexl é uma boa escolha.
Por outro lado, o pacote xlsx já é um pacote antigo, tendo sido uma das primeiras alternativas a surgirem dentro da comunidade de R. Apesar de ser um pacote bastante completo, ele depende de uma biblioteca escrita em Java, e, por causa dessa dependência, é importante que você tenha o Java devidamente instalado e configurado em seu computador, para que você consiga aproveitar de suas funcionalidades. Infelizmente, alguns usuários enfrentam problemas que surgem dessa dependência^[https://www.r-bloggers.com/2021/09/error-java_home-cannot-be-determined-from-the-registry/#:~:text=Approach%201%3A%20error%3A%20JAVA_HOME%20cannot%20be%20determined%20from%20the%20Registry&text=This%20is%20frequently%20due%20to,t%20install%20Java%20at%20all..
Por último, o pacote openxlsx é, em geral, a solução que oferece um equilíbrio entre os dois mundos: é performática, fácil de se utilizar e não possui dependências externas ao pacote. Por esse motivo, vamos utilizar as funções de openxlsx ao longo dos exemplos mostrados neste estudo de caso.
15.8.1 Descrevendo um contexto comum
É frequente termos vários data.frame’s diferentes que desejamos salvar em arquivos de nosso computador. Até o momento, mostramos no capítulo 4 como podemos salvar esses objetos em arquivos CSV, através de funções como readr::write_delim() e readr::write_csv2(). Mas nessa seção, vamos exportar esses data.frame’s para arquivos de Excel.
Como exemplo, vamos utilizar novamente a tabela datasus que introduzimos anteriormente no capítulo 8. Lembrando que você pode importar rapidamente essa tabela para a sua sessão com os comandos abaixo. Ou seja, copie e cole os comandos abaixo em seu console, que você já terá acesso a essa tabela.
library(readr)
github <- "https://raw.githubusercontent.com/pedropark99/"
pasta <- "Curso-R/master/Dados/"
arquivo <- "datasus.csv"
datasus <- read_csv2(paste0(github, pasta, arquivo))
print(datasus)## # A tibble: 1,836 × 6
## `Faixa etaria` Genero Cor `Nome UF` UF Contagem
## <chr> <chr> <chr> <chr> <chr> <dbl>
## 1 10 a 14 Feminino Parda Acre AC 4
## 2 10 a 14 Masculino Parda Acre AC 4
## 3 15 a 19 Feminino Branca Acre AC 2
## 4 15 a 19 Feminino Parda Acre AC 4
## 5 15 a 19 Masculino Branca Acre AC 6
## 6 15 a 19 Masculino Parda Acre AC 65
## 7 15 a 19 Masculino Preta Acre AC 1
## 8 20 a 24 Feminino Indígena Acre AC 1
## 9 20 a 24 Feminino Parda Acre AC 4
## 10 20 a 24 Masculino Branca Acre AC 7
## # ℹ 1,826 more rows15.8.2 Como exportar uma tabela para um arquivo de Excel
Para escrevermos uma planilha de Excel (.xlsx) com o pacote openxlsx, temos que seguir basicamente quatro passos: 1) criar um workbook vazio com a função createWorkbook(); 2) adicionar uma nova página a esse workbook, com a função addWorksheet(); 3) escrever os dados do data.frame em questão nessa nova página adicionada ao workbook, com a função writeData(); 3) por último, exportar esse workbook (ou essa planilha) com a função saveWorkbook().
Em resumo, todas as planilhas de Excel criadas pelo pacote openxlsx são representadas no R através de um “workbook” (em termos mais técnicos, isto é um objeto de classe "Workbook"). Portanto, sempre que estamos trabalhando com as funções do pacote openxlsx, seja adicionando dados a essa planilha, ou alterando suas configurações, estamos na realidade, aplicando essas funções sobre o workbook que representa essa planilha de Excel no R.
Tendo isso em mente, você vai acabar percebendo que a grande maioria das funções do pacote openxlsx recebem em seu primeiro argumento, o workbook que armazena a sua planilha. Nos exemplos dessa seção, eu vou sempre armazenar esse workbook em um objeto chamado wb. Para criarmos um workbook, podemos utilizar a função createWorkbook(), como demonstrado abaixo:
library(openxlsx)
## Criando um workbook vazio:
wb <- createWorkbook()Porém, essa função createWorkbook() cria a representação de uma planilha completamente vazia. Por isso, precisamos adicionar um novo sheet à essa planilha. Em outras palavras, é como se estivéssemos adicionando à essa planilha, uma nova folha de papel, onde podemos escrever os nossos dados. Para adicionarmos essa nova página (ou sheet), podemos utilizar a função addWorksheet(). Após executarmos essa função no exemplo abaixo, o workbook armazenado no objeto wb passa a conter uma nova página chamada “Dados DATASUS”.
## Adicionando uma nova página (ou sheet) nesse workbook:
addWorksheet(wb, "Dados DATASUS")Após adicionarmos essa nova página, podemos escrever os nossos dados nela, com a função writeData(). Para utilizar essa função, você fornece o seu workbook no primeiro argumento, o nome da página na qual você deseja escrever esses dados (nesse caso, a página “Dados DATASUS”) no segundo argumento, e os dados em questão a serem escritos no terceiro argumento.
## Escrevendo os dados da tabela datasus
## nessa nova página:
writeData(wb, "Dados DATASUS", datasus)Sendo assim, o nosso workbook wb já contém os dados da tabela datasus escritos em uma página chamada “Dados DATASUS”. Por último, precisamos apenas exportar esse workbook para um arquivo de Excel (.xslx). Para isso, podemos utilizar a função saveWorkbook(). Após executar o comando abaixo, um novo arquivo .xlsx chamado "dados-datasus" é criado em meu diretório de trabalho, contendo os dados da tabela datasus.
## Por último exportando os dados:
saveWorkbook(wb, "dados-datasus.xlsx")15.8.3 Como salvar múltiplas planilhas de Excel
Agora que sabemos quais são os passos necessários para salvar uma única planilha, podemos pensar em como podemos salvar múltiplas planilhas diferentes. Como exemplo, vamos dividir a tabela datasus, em várias tabelas menores. Mais especificamente, vamos dividir essa tabela por cada UF (Unidade da Federação). Para isso, podemos utilizar a função split():
por_uf <- split(datasus, ~UF)Agora, o objeto por_uf é uma lista de 27 elementos. Cada elemento, contém um data.frame com os dados de uma UF específica. Por exemplo, com o comando abaixo, podemos acessar os dados de Minas Gerais (MG).
por_uf[["MG"]]## # A tibble: 89 × 6
## `Faixa etaria` Genero Cor `Nome UF` UF Contagem
## <chr> <chr> <chr> <chr> <chr> <dbl>
## 1 10 a 14 Feminino Branca Minas Gerais MG 1
## 2 10 a 14 Feminino Parda Minas Gerais MG 3
## 3 10 a 14 Feminino Preta Minas Gerais MG 1
## 4 10 a 14 Masculino Branca Minas Gerais MG 3
## 5 10 a 14 Masculino Parda Minas Gerais MG 11
## 6 10 a 14 Masculino Preta Minas Gerais MG 2
## 7 15 a 19 Feminino Branca Minas Gerais MG 16
## 8 15 a 19 Feminino Parda Minas Gerais MG 21
## 9 15 a 19 Feminino Preta Minas Gerais MG 6
## 10 15 a 19 Masculino Branca Minas Gerais MG 78
## # ℹ 79 more rowsComo podemos exportar uma planilha para cada UF? Para isso, podemos utilizar um for loop sobre o objeto por_uf. O for loop abaixo, vai (a cada repetição) criar um novo objeto wb contendo uma planilha vazia, em seguida, adicionar uma página chamada “Página 1” a essa planilha, depois, escrever os dados de uma UF específica nessa página, e, por último, exportar esses dados para uma planilha com o nome da UF.
A cada repetição do loop, os dados da UF são selecionados através do comando dados_uf <- por_uf[[uf]]. Após executar o for loop abaixo, você deve ter 27 novas planilhas em seu diretório de trabalho.
ufs <- names(por_uf)
for(uf in ufs){
## Selecionando os dados da UF
dados_uf <- por_uf[[uf]]
## Criando o workbook vazio
wb <- createWorkbook()
## Adicionando uma página padrão:
addWorksheet(wb, "Página 1")
## Escrevendo os dados da UF na nova página
writeData(wb, "Página 1", dados_uf)
## Salvando o workbook em uma planilha
saveWorkbook(wb, paste(uf, ".xlsx", collapse = ""))
}15.8.4 Salvando os dados em diferentes páginas de uma mesma planilha
Portanto, já vimos como podemos salvar uma única planilha, e, também, várias planilhas de uma vez só com um for loop. Porém, podemos ainda salvar os dados de cada UF em páginas separadas de uma mesma planilha do Excel. Ou seja, podemos criar um único arquivo de Excel, contendo 27 páginas. Cada página, contém os dados de uma UF específica.
Perceba que o problema continua o mesmo: queremos exportar os dados de cada UF para locais separados. Todavia, a forma como estamos separando esses dados se modificou, pois agora, estamos separando por páginas de uma planilha, ao invés de separarmos por planilha. Para executarmos essa tarefa, podemos novamente aplicar um for loop sobre o objeto por_uf.
Perceba abaixo, que o corpo do loop é quase idêntico ao do exemplo anterior, contendo algumas poucas alterações. Dessa vez, o workbook wb é criado fora do loop, pois queremos salvar todos os dados no mesmo workbook (ou na mesma planilha). Ou seja, nós não queremos redefinir esse workbook a cada repetição do loop, mas sim, adicionar mais conteúdo a ele. Repare também, que a função addWorksheet() também cumpre um papel importante dessa vez, dado que ela é responsável por criar as páginas na planilha para cada UF.
Logo, a cada repetição do loop abaixo, estamos adicionando uma nova página ao workbook wb com o nome de uma UF, e escrevendo nessa nova página adicionada, os dados da UF correspondente. Após a execução do loop, o workbook wb já contém todas as 27 páginas com os dados de cada UF. Tudo o que precisamos fazer ao final é exportar esse workbook para uma planilha chamada "dados-datasus", com a função saveWorkbook().
ufs <- names(por_uf)
wb <- createWorkbook()
for(uf in ufs){
## Selecionando os dados da UF:
dados_uf <- por_uf[[uf]]
## Adicionando uma nova página ao workbook:
addWorksheet(wb, uf)
## Escrevendo os dados da UF nessa página:
writeData(wb, uf, dados_uf)
}
saveWorkbook(wb, "dados-datasus.xlsx")15.9 Sobre código vetorizado (vectorized code)
Na comunidade do R, os loop’s não são particularmente incentivados como em outras linguagens de programação. Programas escritos em linguagens como C, C++ e Python quase sempre utilizam loop’s de forma massiva, algo que nem sempre ocorre em programas escritos em R.
Tal diferença ocorre por dois motivos: 1) R é uma linguagem funcional, logo, quando precisamos utilizar um loop, ao invés de defini-lo explicitamente, nós geralmente aplicamos uma função que constrói esse loop por nós (WICKHAM; GROLEMUND, 2017); 2) para mais, o R é uma linguagem focada em cálculos vetorizados (GROLEMUND, 2014). Isto significa que a linguagem R prefere trabalhar em seus cálculos, com todo o vetor (ou todo o objeto) de uma vez só, ao invés de trabalhar sequencialmente com cada um dos elementos desse objeto de forma individual.
Por essa característica, programas em R, usualmente se aproveitam de três características: testes lógicos, subsetting e cálculos por elemento, ou element-wise execution (GROLEMUND, 2014). Pois essas características são o que o R faz de melhor.
Uma soma entre dois vetores, é um bom exemplo que demonstra como essa noção de element-wise execution está enraizada na forma como o R realiza os seus cálculos. Para somarmos dois vetores no R, precisamos apenas conectar esses dois vetores pelo operador +. Perceba que isso é algo muito simples e direto.
vetor1 <- 1:5
vetor2 <- c(10, 20, 30, 40, 50)
vetor1 + vetor2## [1] 11 22 33 44 55Contudo, para realizarmos esse mesmo trabalho em outras linguagens, temos um trabalho maior, pois essas outras linguagens operam de uma forma completamente diferente do R. Perceba que nos dois exemplos abaixo, ambas as soluções apresentadas dependem de um for loop. Como um primeiro exemplo, eu poderia reproduzir em C, a soma entre os objetos vetor1 e vetor2 da seguinte forma:
int vetor1[5] = {
1,2,3,4,5
};
int vetor2[5] = {
10,20,30,40,50
};
int soma[5];
for (int i = 0; i < 5; i++) {
soma[i] = vetor1[i] + vetor2[i];
printf("%d ", soma[i]);
}## 11 22 33 44 55Como um segundo exemplo, eu poderia reproduzir essa mesma soma em Python da seguinte maneira:
vetor1 = [1, 2, 3, 4, 5]
vetor2 = [10, 20, 30, 40, 50]
soma = []
for i in range(len(vetor1)):
soma.append(vetor1[i] + vetor2[i])
print(soma)## [11, 22, 33, 44, 55]Portanto, enquanto linguagens como Python e C executam seus cálculos em uma perspectiva mais “incremental” (uma operação de cada vez), o R prefere realizar esses mesmos cálculos em uma perspectiva mais “vetorizada”, lidando com todo o objeto de uma vez só. A figura 15.3 abaixo, apresenta tal diferença de maneira gráfica.
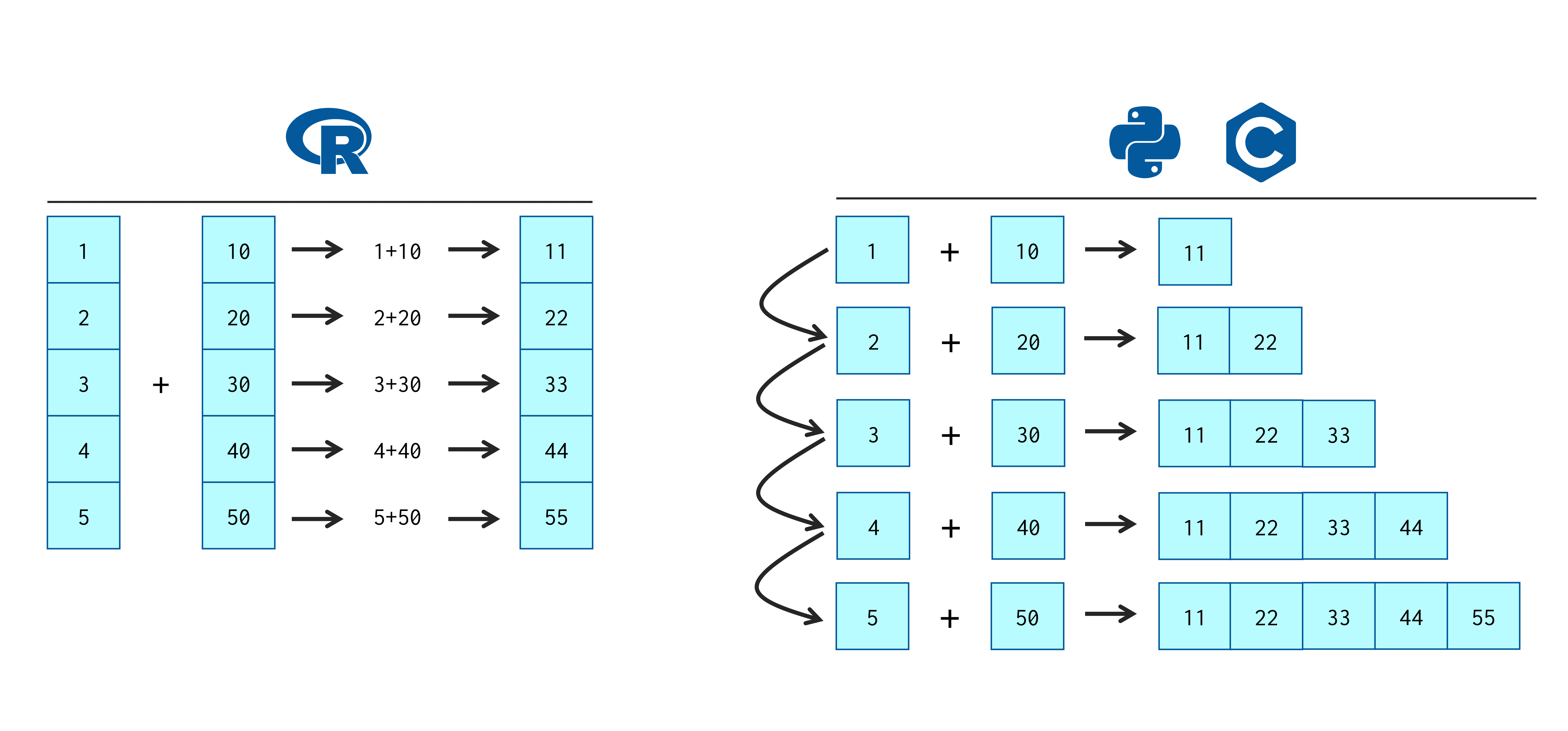
Figura 15.3: Como a soma entre dois vetores é executada em diferentes linguagens de programação
GROLEMUND (2014) é provavelmente o autor que melhor destacou essa diferença entre o R e outras linguagens. Como exemplo, GROLEMUND (2014) mostrou a diferença entre duas funções (abs_loop() e abs_vec()) que aceitam um vetor numérico como input, e que retornam um novo vetor contendo os valores absolutos dos números contidos no vetor de input.
Em outras palavras, ambas as funções são equivalentes à função abs() dos pacotes básicos do R. Porém, elas realizam os seus cálculos de maneiras bastante distintas. A função abs_loop() utiliza um for loop para visitar individualmente cada elemento do vetor de input, e multiplica esse elemento por -1 caso ele seja menor que 0. Logo, abs_loop() adota uma perspectiva semelhante às linguagens C e Python. Por outro lado, abs_vec() se aproveita das características fortes do R, pois ele primeiro utiliza um teste lógico para detectar todos os elementos do vetor que precisam ser ajustados, e, em seguida, multiplica todos esses elementos por -1 de uma vez só.
abs_loop <- function(vec){
for(i in seq_along(vec)){
if(vec[i] < 0){
vec[i] <- vec[i] * -1
}
}
return(vec)
}
abs_vec <- function(vec){
negative <- vec < 0
vec[negative] <- vec[negative] * -1
return(vec)
}Realizei um teste rápido em meu computador, aplicando ambas as funções sobre um vetor de 100 milhões de elementos. Os resultados da função abs_loop() são de certa forma impressionantes, pois eles mostram claramente uma grande evolução da linguagem nos últimos anos.
Na época, GROLEMUND (2014) realizou este mesmo teste com um vetor de 5 milhões de observações, e a função abs_loop() demorou em torno de 16 segundos para sua execução. Porém, hoje, em 2021, utilizando uma instalação do R no Windows, em sua versão 4.1.0, adquirimos praticamente os mesmos 16 segundos sobre um vetor 20 vezes maior que o vetor utilizado por GROLEMUND (2014). Isso mostra uma grande melhoria de performance dos loops construídos pela linguagem nos últimos anos.
system.time({
abs_loop(rnorm(100000000))
})## usuário sistema decorrido
## 15.99 0.29 16.34
system.time({
abs_vec(rnorm(100000000))
})## usuário sistema decorrido
## 9.05 0.45 9.58Obviamente, parte dessa melhoria se deve ao hardware atual, que provavelmente é mais rápido e moderno que o hardware utilizado na época de GROLEMUND (2014). Mesmo assim, um ganho de performance de 20 vezes não pode ser atribuído apenas ao hardware de um notebook de entrada como o meu, que inclui 8GB de RAM e um processador lançado ao mercado no início de 2017. Parte desses resultados se devem à otimizações da própria linguagem, que foi se aprimorando ao longo dos anos.
Para fins de comparação, mesmo que eu reproduza exatamente o mesmo teste realizado por GROLEMUND (2014), podemos perceber não apenas o grande ganho de abs_loop(), mas também, de abs_vec(). Nos testes de GROLEMUND (2014), as funções abs_loop() e abs_vec() demoraram 16,018 e 0,52 segundos, respectivamente. Por outro lado, perceba pelos resultados dos testes abaixo (realizados no meu computador), que essas mesmas funções levaram apenas 0,77 e 0,11 segundos. O que realmente impressiona nesses resultados, é como a função abs_loop() se aproximou bastante da performance apresentada por abs_vec().
long <- rep(c(-1, 1), 5000000)
system.time({
abs_loop(long)
})## usuário sistema decorrido
## 0.76 0.00 0.77
system.time({
abs_vec(long)
})## usuário sistema decorrido
## 0.09 0.02 0.11 Este tipo de resultado, demonstra que os loops no R são muito mais rápidos do que a maior parte dos usuários imagina. Essa é uma polêmica antiga na comunidade internacional de R, onde a ideia de que loops no R são lentos e ineficientes acabou sendo difundida em massa. Parte da culpa não reside apenas nos usuários, dado que o próprio manual interno e introdutório da linguagem desincentiva o uso de loops:
Warning:
for()loops are used in R code much less often than in compiled languages. Code that takes a ‘whole object’ view is likely to be both clearer and faster in R. (TEAM, 2020b, p 41)
Uma outra parte da fonte que incentivou o surgimento dessa polêmica, foi o simples fato de que o R é uma linguagem funcional. Portanto, loops explícitos no R são mais incomuns do que em outras linguagens. Por esse motivo, muitos usuários acabaram pressupondo que loops explícitos fossem algo ruim no R.
O que muitos não percebem, é que mesmo com esses pressupostos, nós ainda utilizamos loops em diversas situações no R. Porém, quando essas situações ocorrem, esse loop geralmente está “escondido” atrás de uma função. Ou seja, ao invés de construirmos um loop explícito, nós utilizamos uma função que constrói, por nós, esse loop de forma implícita. Exemplos disso são as funções lapply() e purrr::map().
Concluindo, os resultados acima demonstram que a linguagem R oferece sim, loops rápidos e eficientes, que podem produzir uma boa performance. Entretanto, ainda assim, as soluções vetorizadas continuam sendo as mais performáticas, e mesmo com o bom desempenho apresentado, os loops do R não se escalam tão bem quanto os loops de outras linguagens como C e C++.
Por esse motivo, muitos usuários do R, quando enfrentam um problema mais complexo que exige o uso intensivo de loops, utilizam interfaces (como a API fornecida pelo pacote Rcpp) para reescrever os seus loops em linguagens mais performáticas como C++. O artigo de introdução64 do pacote Rcpp oferece bons exemplos onde isso ocorre, mostrando também como você pode acessar, através do R, funções escritas em C++.
Na prática, isso significa que, se você deseja adquirir a melhor performance possível no R, tente escrever um código sob uma perspectiva “vetorizada”, que se aproveita das 3 características principais do R (subsetting, testes lógicos e element-wise execution). Entretanto, não tenha medo ou receio de utilizar loops em seu código, pois eles também conseguem entregar uma boa performance.
Contudo, se os loops do R não são rápidos o suficiente para o seu problema, tente utilizar alguma interface para reescrever esses loops em linguagens mais performáticas, como C e C++. O R oferece de fábrica uma API para a linguagem C, que está descrita no capítulo 5 do manual Writing R Extensions65. Mas você também pode utilizar o pacote Rcpp para acessar funções escritas em C++.
Exercícios
Questão 15.1. Responda as questões abaixo:
15.1.A) O que acontece se executarmos o for loop abaixo:
15.1.B) Porque o loop abaixo é um loop infinito?
15.1.C) Quantas vezes o for loop abaixo vai repetir os comandos descritos em seu body?
df <- data.frame(id = 1:10)
for(name in letters[1:24]){
df[[name]] <- NA
}15.1.D) Porque o for loop abaixo está retornando numeric(0) na segunda iteração? Qual é a fonte do erro?
## [1] 2
## numeric(0)Questão 15.2. Crie um loop que seja capaz de encontra o valor máximo do vetor vec abaixo. Em outras palavras, construa um loop que consiga encontrar o mesmo resultado do comando max(vec).
vec <- c(
5.2, 6.1, 2.3, 7.4, 1.1, 3.6,
7.2, 8.1, 3.3, 4.5, 0.8, 5.4
)Questão 15.3. Ao longo deste capítulo, nós não mostramos um exemplo de um loop aninhado (nested loop), isto é, um loop que contém um outro loop dentro de si. Porém, é completamente permitido que você construa camadas e camadas de loops desta maneira. Seu objetivo neste exercício é desenvolver um loop aninhado que preencha a matriz mt abaixo. Ao final do loop, cada elemento dessa matriz deve conter o resultado da multiplicação dos índices que localizam esse elemento nessa matriz. Ou seja, o elemento da 9° linha da 10° coluna, deve conter o valor \(9 \times 10 = 90\); já o elemento da 15° linha da 3° coluna, deve conter o valor \(15 \times 3 = 45\); e assim por diante.
mt <- matrix(ncol = 30, nrow = 30)