Capítulo 6 Introdução a base de dados relacionais com dplyr
6.1 Introdução e pré-requisitos
Segundo NIELD (2016, p 53), joins são uma das funcionalidades que definem a linguagem SQL (Structured Query Language). Por isso, joins são um tipo de operação muito relacionado à RDBMS (Relational DataBase Management Systems), que em sua maioria, utilizam a linguagem SQL. Logo, essa seção será muito familiar para aqueles que possuem experiência com essa linguagem.
Para executarmos uma operação de join, os pacotes básicos do R oferecem a função merge(). Entretanto, vamos abordar o pacote dplyr neste capítulo, que também possui funções especializadas neste tipo de operação. Com isso, para ter acesso às funções que vamos mostrar aqui, você pode chamar tanto pelo pacote dplyr quanto pelo tidyverse.
6.2 Dados relacionais e o conceito de key
Normalmente, trabalhamos com diversas bases de dados diferentes ao mesmo tempo. Pois é muito incomum, que uma única tabela contenha todas as informações das quais necessitamos e, por isso, transportar os dados de uma tabela para outra se torna uma atividade essencial em muitas ocasiões.
Logo, de alguma maneira, os dados presentes nessas diversas tabelas se relacionam entre si. Por exemplo, suponha que você possua uma tabela contendo o PIB dos municípios do estado de Minas Gerais, e uma outra tabela contendo dados demográficos desses mesmos municípios. Se você deseja unir essas duas tabelas em uma só, você precisa de algum mecanismo que possa conectar um valor do município X na tabela A com a linha da tabela B correspondente ao mesmo município X, e através dessa conexão, conduzir o valor da tabela A para esse local específico da tabela B, ou vice-versa. O processo que realiza esse cruzamento entre as informações, e que por fim, mescla ou funde as duas tabelas de acordo com essas conexões, é chamado de join.
Por isso, dizemos que os nossos dados são “relacionais”. Pelo fato de que nós possuímos diversas tabelas que descrevem os mesmos indivíduos, municípios, firmas ou eventos. Mesmo que essas tabelas estejam trazendo variáveis ou informações muito diferentes desses indivíduos, elas possuem essa característica em comum e, com isso, possuem uma relação entre si, e vamos frequentemente nos aproveitar dessa relação para executarmos análises mais completas.
Porém, para transportarmos esses dados de uma tabela a outra, precisamos de alguma chave, ou de algum mecanismo que seja capaz de identificar as relações entre as duas tabelas. Em outras palavras, se temos na tabela A, um valor pertencente ao indivíduo X, e queremos transportar esse valor para a tabela B, nós precisamos de algum meio que possa identificar o local da tabela B que seja referente ao indivíduo X. O mecanismo que permite essa comparação, é o que chamamos de key ou de “chave”.
d <- c("1943-07-26", "1940-09-10", "1942-06-18", "1943-02-25", "1940-07-07")
info <- tibble(
name = c("Mick", "John", "Paul", "George", "Ringo"),
band = c("Rolling Stones", "Beatles", "Beatles", "Beatles", "Beatles"),
born = as.Date(d),
children = c(TRUE)
)
band_instruments <- tibble(
name = c("John", "Paul", "Keith"),
plays = c("guitar", "bass", "guitar")
)Como exemplo inicial, vamos utilizar a tabela info, que descreve características pessoais de um conjunto de músicos famosos. Também temos a tabela band_instruments, que apenas indica qual o instrumento musical utilizado por parte dos músicos descritos na tabela info.
info## # A tibble: 5 × 4
## name band born children
## <chr> <chr> <date> <lgl>
## 1 Mick Rolling Stones 1943-07-26 TRUE
## 2 John Beatles 1940-09-10 TRUE
## 3 Paul Beatles 1942-06-18 TRUE
## 4 George Beatles 1943-02-25 TRUE
## 5 Ringo Beatles 1940-07-07 TRUE
band_instruments## # A tibble: 3 × 2
## name plays
## <chr> <chr>
## 1 John guitar
## 2 Paul bass
## 3 Keith guitarPortanto, precisamos de uma key para detectarmos as relações entre as tabelas info e band_instruments. Uma key consiste em uma variável (ou um conjunto de variáveis), que é capaz de identificar unicamente cada indivíduo descrito em uma tabela, sendo que essa variável (ou esse conjunto de variáveis), deve obrigatoriamente estar presente em ambas as tabelas em que desejamos aplicar o join. Dessa forma, podemos através dessa variável, discernir quais indivíduos estão presentes nas duas tabelas, e quais se encontram em apenas uma delas.
Ao observar as tabelas info e band_instruments, você talvez perceba que ambas possuem uma coluna denominada name. No nosso caso, essa é a coluna que representa a key entre as tabelas info e band_instruments. Logo, ao identificar o músico que está sendo tratado em cada linha, a coluna name nos permite cruzar as informações existentes em ambas tabelas. Com isso, podemos observar que os músicos John e Paul, estão disponíveis em ambas as tabelas, mas os músicos Mick, George e Ringo estão descritos apenas na tabela info, enquanto o músico Keith se encontra apenas na tabela band_instruments.
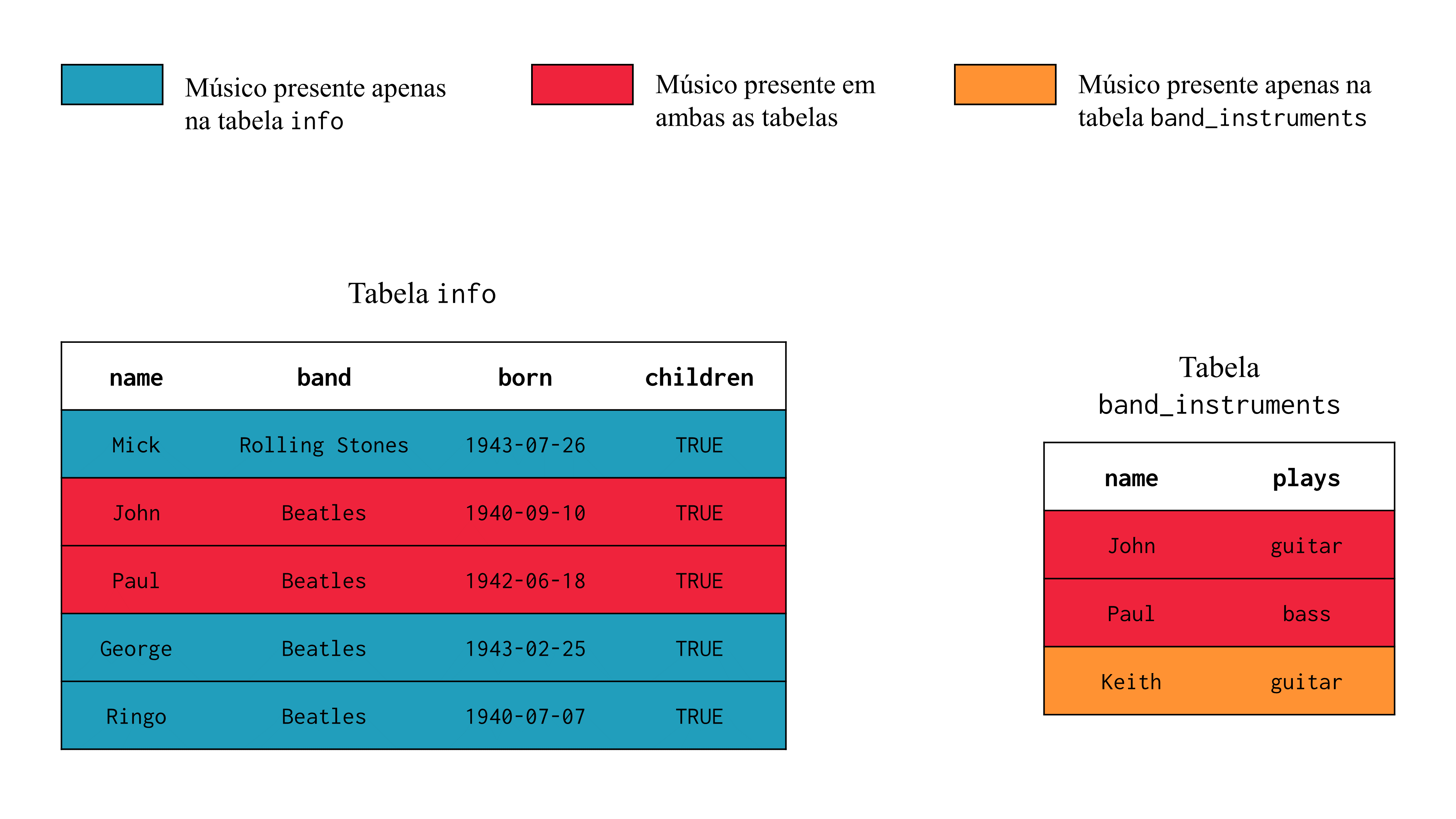
Figura 6.1: Cruzamento entre as tabelas info e
Segundo NIELD (2016), podemos ter dois tipos de keys existentes em uma tabela:
Primary key: uma variável capaz de identificar unicamente cada uma das observações presentes em sua tabela.
Foreign key: uma variável capaz de identificar unicamente cada uma das observações presentes em uma outra tabela.
Com essas características em mente, podemos afirmar que a coluna name existente nas tabelas info e band_instruments, se trata de uma primary key. Pois em ambas as tabelas, mais especificamente em cada linha dessa coluna, temos um músico diferente, ou em outras palavras, não há um músico duplicado.
Por outro lado, uma foreign key normalmente contém valores repetidos ao longo da base e, por essa razão, não são capazes de identificar unicamente uma observação na tabela em que se encontram. Porém, os valores de uma foreign key certamente fazem referência a uma primary key existente em uma outra tabela. Tendo isso em mente, o objetivo de uma foreign key não é o de identificar cada observação presente em uma tabela, mas sim, de indicar ou explicitar a relação que a sua tabela possui com a primary key presente em uma outra tabela.
Por exemplo, suponha que eu tenha a tabela children abaixo. Essa tabela descreve os filhos de alguns músicos famosos, e a coluna father caracteriza-se como a foreign key dessa tabela. Não apenas porque os valores da coluna father se repetem ao longo da base, mas também, porque essa coluna pode ser claramente cruzada com a coluna name pertencente às tabelas info e band_instruments.
children <- tibble(
child = c("Stella", "Beatrice", "James", "Mary",
"Heather", "Sean", "Julian", "Zak",
"Lee", "Jason", "Dhani"),
sex = c("F", "F", "M", "F", "F", "M", "M", "M", "F", "M", "M"),
father = c(rep("Paul", times = 5), "John", "John",
rep("Ringo", times = 3), "Harrison")
)
children## # A tibble: 11 × 3
## child sex father
## <chr> <chr> <chr>
## 1 Stella F Paul
## 2 Beatrice F Paul
## 3 James M Paul
## 4 Mary F Paul
## 5 Heather F Paul
## 6 Sean M John
## 7 Julian M John
## 8 Zak M Ringo
## 9 Lee F Ringo
## 10 Jason M Ringo
## 11 Dhani M Harrison6.3 Introduzindo joins
Tendo esses pontos em mente, o pacote dplyr nos oferece quatro funções voltadas para operações de join. Cada uma dessas funções executam um tipo de join diferente, que vamos comentar na próxima seção. Por agora, vamos focar apenas na função inner_join(), que como o seu próprio nome dá a entender, busca aplicar um inner join.
Para utilizar essa função, precisamos nos preocupar com três argumentos principais. Os dois primeiros argumentos (x e y), definem os data.frame’s a serem fundidos pela função. Já no terceiro argumento (by), você deve delimitar a coluna, ou o conjunto de colunas que representam a key entre as tabelas fornecidas em x e y.
Assim como em qualquer outro tipo de join, as duas tabelas envolvidas serão unidas, porém, em um inner join, apenas as linhas de indivíduos que se encontram em ambas as tabelas serão retornadas na nova tabela gerada. Perceba abaixo, que a função inner_join() criou uma nova tabela contendo todas as colunas presentes nas tabelas info e band_instruments como esperávamos, e que ela manteve apenas as linhas referentes aos músicos John e Paul, que são os únicos indivíduos que aparecem em ambas as tabelas.
inner_join(info, band_instruments, by = "name")## # A tibble: 2 × 5
## name band born children plays
## <chr> <chr> <date> <lgl> <chr>
## 1 John Beatles 1940-09-10 TRUE guitar
## 2 Paul Beatles 1942-06-18 TRUE bass
## -----------------------------------------------
## A mesma operação com o uso do pipe ( %>% ):
info %>%
inner_join(band_instruments, by = "name")Ao observar esse resultado, você talvez chegue à conclusão de que um processo de join se trata do mesmo processo executado pela função PROCV() do Excel. Essa é uma ótima comparação! Pois a função PROCV() realiza justamente um join parcial, ao trazer para a tabela A, uma coluna pertencente a tabela B, de acordo com uma key que conecta as duas tabelas.
Por outro lado, nós não podemos afirmar que a função PROCV() busca construir um join per se. Pois um join consiste em um processo de união, em que estamos literalmente fundindo duas tabelas em uma só. Já a função PROCV(), é capaz de transportar apenas uma única coluna por tabela, logo, não é de sua filosofia, fundir as tabelas envolvidas. Por isso, se temos cinco colunas em uma tabela A, as quais desejamos levar até a tabela B, nós precisamos de cinco PROCV()’s diferentes no Excel, enquanto no R, precisamos de apenas um inner_join() para realizarmos tal ação.
Por último, vale destacar uma característica muito importante de um join, que é o seu processo de pareamento. Devido a essa característica, a ordem das linhas presentes em ambas as tabelas se torna irrelevante para o resultado. Por exemplo, veja na figura 6.2, um exemplo de join, onde a coluna ID representa a key entre as duas tabelas. Repare que as linhas na tabela à esquerda que se referem, por exemplo, aos indivíduos de ID 105, 107 e 108, se encontram em linhas diferentes na tabela à direita. Mesmo que esses indivíduos estejam em locais diferentes, a função responsável pelo join, vai realizar um pareamento entre as duas tabelas, antes de fundi-las. Dessa maneira, podemos nos certificar que as informações de cada indivíduo são corretamente posicionadas na tabela resultante.
Figura 6.2: Representação de um join entre duas tabelas
6.4 Configurações sobre as colunas e keys utilizadas no join
Haverá momentos em que uma única coluna não será o bastante para identificarmos cada observação de nossa base. Por isso, teremos oportunidades em que devemos utilizar a combinação entre várias colunas, com o objetivo de formarmos uma primary key em nossa tabela.
Por exemplo, suponha que você trabalhe diariamente com o registro de entradas no estoque de um supermercado. Imagine que você possua a tabela registro abaixo, que contém dados da seção de bebidas do estoque, e que apresentam o dia e mes em que uma determinada carga chegou ao estoque da empresa, além de uma descrição de seu conteúdo (descricao), seu valor de compra (valor) e as unidades inclusas (unidades).
registro <- tibble(
dia = c(3, 18, 18, 25, 25),
mes = c(2, 2, 2, 2, 3),
ano = 2020,
unidades = c(410, 325, 325, 400, 50),
valor = c(450, 1400, 1150, 670, 2490),
descricao = c("Fanta Laranja 350ml",
"Coca Cola 2L", "Mate Couro 2L",
"Kapo Uva 200ml", "Absolut Vodka 1L")
)
registro## # A tibble: 5 × 6
## dia mes ano unidades valor descricao
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 3 2 2020 410 450 Fanta Laranja 350ml
## 2 18 2 2020 325 1400 Coca Cola 2L
## 3 18 2 2020 325 1150 Mate Couro 2L
## 4 25 2 2020 400 670 Kapo Uva 200ml
## 5 25 3 2020 50 2490 Absolut Vodka 1LNessa tabela, as colunas dia, mes, ano, valor, unidades e descricao, sozinhas, são insuficientes para identificarmos cada carga registrada na tabela. Mesmo que, atualmente, cada valor presente na coluna descricao seja único, essa característica provavelmente não vai resistir por muito tempo. Pois o supermercado pode muito bem receber amanhã, por exemplo, uma outra carga de refrigerantes de 2 litros da Mate Couro.
Por outro lado, a combinação dos valores presentes nas colunas dia, mes, ano, valor, unidades e descricao, pode ser o suficiente para criarmos um código de identificação único para cada carga. Por exemplo, ao voltarmos à tabela registro, podemos encontrar duas cargas que chegaram no mesmo dia 18, no mesmo mês 2, no mesmo ano de 2020, e trazendo as mesmas 325 unidades. Todavia, essas duas cargas, possuem descrições diferentes: uma delas incluía garrafas preenchidas com Coca Cola, enquanto a outra, continha Mate Couro. Concluindo, ao aliarmos as informações referentes a data de entrada (18/02/2020), as quantidades inclusas nas cargas (325 unidades), e as suas descrições (Coca Cola 2L e Mate Couro 2L), podemos enfim diferenciar essas duas cargas:
Uma carga que entrou no dia 18/02/2020, incluía 325 unidades de 2 litros de Coca Cola.
Uma carga que entrou no dia 18/02/2020, incluía 325 unidades de 2 litros de Mate Couro.
Como um outro exemplo, podemos utilizar as bases flights e weather, provenientes do pacote nycflights13. Perceba abaixo, que a base flights já possui um número grande colunas. Essa tabela apresenta dados diários, referentes a diversos voos que partiram da cidade de Nova York (EUA) durante o ano de 2013. Já a tabela weather, contém dados meteorológicos em uma dada hora, e em diversas datas do mesmo ano, e que foram especificamente coletados nos aeroportos da mesma cidade de Nova York.
flights## # A tibble: 336,776 × 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ℹ 336,766 more rows
## # ℹ 12 more variables: sched_arr_time <dbl>, arr_delay <dbl>,
## # carrier <chr>, flight <dbl>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm>
weather## # A tibble: 26,115 × 15
## origin year month day hour temp dewp humid wind_dir wind_speed
## <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4
## 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06
## 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5
## 4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7
## 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7
## 6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5
## 7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0
## 8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4
## 9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0
## 10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8
## # ℹ 26,105 more rows
## # ℹ 5 more variables: wind_gust <dbl>, precip <dbl>, pressure <dbl>,
## # visib <dbl>, time_hour <dttm>Ao aplicarmos um join entre essas tabelas, poderíamos analisar as características meteorológicas que um determinado avião enfrentou ao levantar voo. Entretanto, necessitaríamos empregar ao menos cinco colunas diferentes para formarmos uma key adequada entre essas tabelas. Pois cada situação meteorológica descrita na tabela weather, ocorre em um uma dada localidade, e em um horário específico de um determinado dia. Com isso, teríamos de utilizar as colunas: year, month e day para identificarmos a data correspondente a cada situação; mais a coluna hour para determinarmos o momento do dia em que essa situação ocorreu; além da coluna origin, que marca o aeroporto de onde cada voo partiu e, portanto, nos fornece uma localização no espaço geográfico para cada situação meteorológica.
Portanto, em todos os momentos em que você precisar utilizar um conjunto de colunas para formar uma key, como o caso das tabelas weather e flights acima, você deve fornecer um vetor contendo o nome dessas colunas para o argumento by da função de join que está utilizando, assim como no exemplo abaixo.
inner_join(
flights,
weather,
by = c("year", "month", "day", "hour", "origin")
)## # A tibble: 335,220 × 29
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ℹ 335,210 more rows
## # ℹ 22 more variables: sched_arr_time <dbl>, arr_delay <dbl>,
## # carrier <chr>, flight <dbl>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour.x <dttm>, temp <dbl>, dewp <dbl>, humid <dbl>,
## # wind_dir <dbl>, wind_speed <dbl>, wind_gust <dbl>, precip <dbl>,
## # pressure <dbl>, visib <dbl>, time_hour.y <dttm>Porém, a tabela flights já possui um número muito grande colunas e, por essa razão, não conseguimos visualizar no resultado do join, as diversas colunas importadas da tabela weather. Sabemos que um join gera, por padrão, uma nova tabela contendo todas as colunas de ambas as tabelas utilizadas. Contudo, o exemplo acima demonstra que em certas ocasiões, o uso de muitas colunas pode sobrecarregar a sua visão e, com isso, dificultar o seu foco no que é de fato importante em sua análise.
Tendo isso em mente, haverá instantes em que você deseja trazer apenas algumas colunas de uma das tabelas envolvidas no join. Mas não há como alterarmos a natureza de um join, logo, todas as colunas de ambas as tabelas serão sempre incluídas em seu resultado. Por isso, o ideal é que você selecione as colunas desejadas de uma das tabelas antes de empregá-las em um join.
Ou seja, ao invés de fornecer a tabela completa à função, você pode utilizar ferramentas como select() ou subsetting, para extrair a parte desejada de uma das tabelas, e fornecer o resultado dessa seleção para a função inner_join(). Entretanto, . De outra forma, não se esqueça de incluir em sua seleção, as colunas que você proveu ao argumento by.
Por exemplo, supondo que você precisasse em seu resultado apenas das colunas dep_time e dep_delay da tabela flights, você poderia fornecer os comandos a seguir:
cols_para_key <- c(
"year", # Coluna 1 para key
"month", # Coluna 2 para key
"day", # Coluna 3 para key
"hour", # Coluna 4 para key
"origin" # Coluna 5 para key
)
cols_desejadas <- c("dep_time", "dep_delay")
cols_c <- c(cols_para_key, cols_desejadas)
inner_join(
flights %>% select(all_of(cols_c)),
weather,
by = cols_para_key
)## # A tibble: 335,220 × 17
## year month day hour origin dep_time dep_delay temp dewp humid
## <int> <int> <int> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 5 EWR 517 2 39.0 28.0 64.4
## 2 2013 1 1 5 LGA 533 4 39.9 25.0 54.8
## 3 2013 1 1 5 JFK 542 2 39.0 27.0 61.6
## 4 2013 1 1 5 JFK 544 -1 39.0 27.0 61.6
## 5 2013 1 1 6 LGA 554 -6 39.9 25.0 54.8
## 6 2013 1 1 5 EWR 554 -4 39.0 28.0 64.4
## 7 2013 1 1 6 EWR 555 -5 37.9 28.0 67.2
## 8 2013 1 1 6 LGA 557 -3 39.9 25.0 54.8
## 9 2013 1 1 6 JFK 557 -3 37.9 27.0 64.3
## 10 2013 1 1 6 LGA 558 -2 39.9 25.0 54.8
## # ℹ 335,210 more rows
## # ℹ 7 more variables: wind_dir <dbl>, wind_speed <dbl>, wind_gust <dbl>,
## # precip <dbl>, pressure <dbl>, visib <dbl>, time_hour <dttm>
## ----------------------------------------
## Ou por subsetting:
inner_join(
flights[ , cols_c],
weather,
by = cols_para_key
)Antes de partirmos para a próxima seção, vale a pena comentar sobre um outro aspecto importante em um join. As colunas que formam a sua key devem estar nomeadas da mesma maneira em ambas as tabelas. Por exemplo, se nós voltarmos às tabelas info e band_instruments, e renomearmos a coluna name para member em uma das tabelas, um erro será levantado ao tentarmos aplicar novamente um join sobre as tabelas.
colnames(band_instruments)[1] <- "member"
inner_join(info, band_instruments, by = "name")Erro: Join columns must be present in data.
x Problem with `name`.
Run `rlang::last_error()` to see where the error occurred.Logo, ajustes são necessários sobre o argumento by, de forma a revelarmos para a função responsável pelo join, a existência dessa diferença existente entre os nomes dados às colunas que representam a key entre as tabelas. Fazendo uso dos argumentos x e y como referências, para realizar esse ajuste, você deve igualar o nome dado à coluna da tabela x ao nome dado à coluna correspondente na tabela y, dentro de um vetor - c(), como está demonstrado abaixo.
inner_join(info, band_instruments, by = c("name" = "member"))## # A tibble: 2 × 5
## name band born children plays
## <chr> <chr> <date> <lgl> <chr>
## 1 John Beatles 1940-09-10 TRUE guitar
## 2 Paul Beatles 1942-06-18 TRUE bass6.5 Diferentes tipos de join
Portanto, um join busca construir uma união entre duas tabelas. Porém, podemos realizar essa união de diferentes formas, e até o momento, apresentei apenas uma de suas formas, o inner join, que é executado pela função inner_join(). Nesse método, o join mantém apenas as linhas que puderam ser encontradas em ambas as tabelas. Logo, se um indivíduo está presente na tabela A, mas não se encontra na tabela B, esse indivíduo será descartado em um inner join entre as tabelas A e B. Como foi destacado por WICKHAM; GROLEMUND (2017, p 181), essa característica torna o inner join pouco apropriado para a maioria das análises, pois uma importante perda de observações pode ser facilmente gerada neste processo.
Os demais tipos de joins dos quais podemos nos aproveitar, são comumente chamados de outer joins. Tal nome se deve ao fato de que esses tipos buscam preservar as linhas de pelo menos uma das tabelas envolvidas no join em questão. Sendo eles:
left_join(): mantém todas as linhas da tabela definida no argumentox, ou a tabela à esquerda do join, mesmo que os indivíduos descritos nessa tabela não tenham sido encontrados em ambas as tabelas.right_join(): mantém todas as linhas da tabela definida no argumentoy, ou a tabela à direita do join, mesmo que os indivíduos descritos nessa tabela não tenham sido encontrados em ambas as tabelas.full_join(): mantém todas as linhas de ambas as tabelas definidas nos argumentosxey, mesmo que os indivíduos de uma dessas tabelas não tenham sido encontrados em ambas as tabelas.
Em todas as funções de join mostradas aqui, o primeiro argumento é chamado de x, e o segundo, de y, sendo esses os argumentos que definem as duas tabelas a serem utilizadas no join. Simplificadamente, a diferença entre left_join(), right_join() e full_join() reside apenas em quais linhas das tabelas utilizadas, são conservadas por essas funções no produto final do join. Como essas diferenças são simples, as descrições acima já lhe dão uma boa ideia de quais serão as linhas conservadas em cada função. Todavia, darei a seguir, uma visão mais formal desses comportamentos, com o objetivo principal de fornecer uma segunda visão que pode, principalmente, facilitar a sua memorização do que cada função faz.
Para seguir esse caminho, é interessante que você tente interpretar um join a partir de uma perspectiva mais visual e menos minuciosa do processo. Ao aplicarmos um join entre as tabelas A e B, estamos basicamente, extraindo as colunas da tabela B e as adicionando à tabela A (ou vice-versa). Com isso, temos nessa concepção, a tabela fonte (isto é, a tabela de onde as colunas são retiradas), e a tabela destinatária (ou seja, a tabela para onde essas colunas são levadas). Portanto, segundo esse ponto de vista, o join possui sentido e direção, assim como um vetor em um espaço tridimensional. Pois o processo sempre parte da tabela fonte em direção a tabela destinatária. Dessa forma, em um join, estamos resumidamente extraindo as colunas da tabela fonte e as incorporando à tabela destinatária.
Com isso, eu quero criar a perspectiva, de que a tabela fonte e a tabela destinatária, ocupam lados do join, como na figura 6.3. Ou seja, por esse ângulo, estamos compreendendo o join como uma operação que ocorre sempre da direita para esquerda, ou um processo em que estamos sempre carregando um conjunto de colunas da tabela à direita em direção a tabela à esquerda. Se mesclarmos essa visão, com as primeiras descrições dos outer joins que fornecemos, temos que o argumento x corresponde a tabela destinatária, e o argumento y, a tabela fonte. Dessa maneira, a tabela destinatária (ou o argumento x) é sempre a tabela que ocupa o lado esquerdo do join, enquanto a tabela fonte (ou o argumento y) sempre se trata da tabela que ocupa o lado direito da operação.
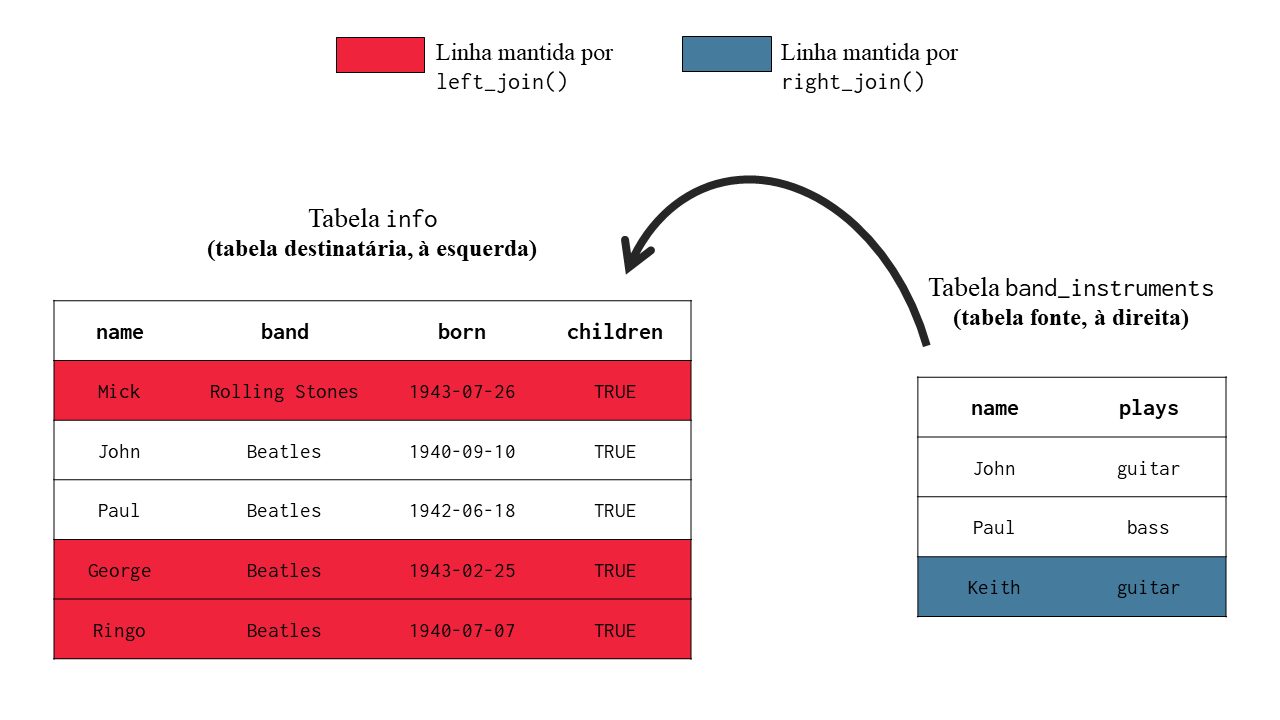
Figura 6.3: As tabelas ocupam lados em um join
Logo, a função left_join() busca manter as linhas da tabela destinatária (ou a tabela que você definiu no argumento x da função) intactas no resultado do join. Isso significa, que caso a função left_join() não encontre na tabela fonte, uma linha que corresponde a um certo indivíduo presente na tabela destinatária, essa linha será mantida no resultado final do join. Porém, como está demonstrado abaixo, em todas as situações em que a função não pôde encontrar esse indivíduo na tabela fonte, left_join() vai preencher as linhas correspondentes nas colunas que ele transferiu dessa tabela, com valores NA, indicando justamente que não há informações daquele respectivo indivíduo na tabela fonte.
left_join(info, band_instruments, by = "name")## # A tibble: 5 × 5
## name band born children plays
## <chr> <chr> <date> <lgl> <chr>
## 1 Mick Rolling Stones 1943-07-26 TRUE <NA>
## 2 John Beatles 1940-09-10 TRUE guitar
## 3 Paul Beatles 1942-06-18 TRUE bass
## 4 George Beatles 1943-02-25 TRUE <NA>
## 5 Ringo Beatles 1940-07-07 TRUE <NA>Em contrapartida, a função right_join() realiza justamente o processo contrário, ao manter as linhas da tabela fonte (ou a tabela que você forneceu ao argumento y). Por isso, para todas as linhas da tabela fonte que se referem a um indivíduo não encontrado na tabela destinatária, right_join() acaba preenchendo os campos provenientes da tabela destinatária, com valores NA, indicando assim que a função não conseguiu encontrar mais dados sobre aquele indivíduo na tabela destinatária. Você pode perceber esse comportamento, pela linha referente ao músico Keith, que está disponível na tabela fonte, mas não na tabela destinatária.
right_join(info, band_instruments, by = "name")## # A tibble: 3 × 5
## name band born children plays
## <chr> <chr> <date> <lgl> <chr>
## 1 John Beatles 1940-09-10 TRUE guitar
## 2 Paul Beatles 1942-06-18 TRUE bass
## 3 Keith <NA> NA NA guitarPor fim, a função full_join() executa o processo inverso da função inner_join(). Ou seja, se por um lado, a função inner_join() mantém as linhas de todos os indivíduos que puderam ser localizados em ambas as tabelas, por outro, a função full_join() sempre traz todos os indivíduos de ambas as tabelas em seu resultado. Em outras palavras, a função full_join() mantém todas as linhas de ambas as tabelas. De certa forma, a função full_join() busca encontrar sempre o maior número possível de combinações entre as tabelas, e em todas as ocasiões que full_join() não encontra um determinado indivíduo, por exemplo, na tabela B, a função vai preencher os campos dessa tabela B com valores NA para as linhas desse indivíduo. Veja o exemplo abaixo.
full_join(info, band_instruments, by = "name")## # A tibble: 6 × 5
## name band born children plays
## <chr> <chr> <date> <lgl> <chr>
## 1 Mick Rolling Stones 1943-07-26 TRUE <NA>
## 2 John Beatles 1940-09-10 TRUE guitar
## 3 Paul Beatles 1942-06-18 TRUE bass
## 4 George Beatles 1943-02-25 TRUE <NA>
## 5 Ringo Beatles 1940-07-07 TRUE <NA>
## 6 Keith <NA> NA NA guitarComo o primeiro data.frame fornecido à função *_join(), será na maioria das situações, a sua principal tabela de trabalho, o ideal é que você adote o left_join() como o seu padrão de join (WICKHAM; GROLEMUND, 2017). Pois dessa maneira, você evita uma possível perda de observações em sua tabela mais importante.
6.6 Relações entre keys: primary keys são menos comuns do que você pensa
Na seção Dados relacionais e o conceito de key, nós estabelecemos que variáveis com a capacidade de identificar unicamente cada observação de sua base, podem ser caracterizadas como primary keys. Mas para que essa característica seja verdadeira para uma dada variável, os seus valores não podem se repetir ao longo da base, e isso não acontece com tanta frequência na realidade.
Como exemplo, podemos voltar ao join entre as tabelas flights e weather que mostramos na seção Configurações sobre as colunas e keys utilizadas no join. Para realizarmos o join entre essas tabelas, nós utilizamos as colunas year, month, day, hour e origin como key. Porém, a forma como descrevemos essas colunas na seção passada, ficou subentendido que a combinação entre elas foi capaz de formar uma primary key. Bem, porque não conferimos se essas colunas assumem de fato esse atributo:
## # A tibble: 18,906 × 6
## year month day hour origin n
## <int> <int> <int> <dbl> <chr> <int>
## 1 2013 1 1 5 EWR 2
## 2 2013 1 1 5 JFK 3
## 3 2013 1 1 6 EWR 18
## 4 2013 1 1 6 JFK 17
## 5 2013 1 1 6 LGA 17
## 6 2013 1 1 7 EWR 12
## 7 2013 1 1 7 JFK 16
## 8 2013 1 1 7 LGA 21
## 9 2013 1 1 8 EWR 20
## 10 2013 1 1 8 JFK 23
## # ℹ 18,896 more rowsComo podemos ver acima, há diversas combinações entre as cinco colunas que se repetem ao longo da base. Com isso, podemos afirmar que a combinação entre as colunas year, month, day, hour e origin não formam uma primary key. Perceba abaixo, que o mesmo vale para a tabela weather:
## # A tibble: 3 × 6
## year month day hour origin n
## <int> <int> <int> <int> <chr> <int>
## 1 2013 11 3 1 EWR 2
## 2 2013 11 3 1 JFK 2
## 3 2013 11 3 1 LGA 2Portanto, circunstâncias em que não há uma primary key definida entre duas tabelas, são comuns, inclusive em momentos que você utiliza a combinação de todas as colunas disponíveis em uma das tabelas para formar uma key. Com isso, eu quero destacar principalmente, que não há problema algum em utilizarmos foreign keys em joins.
Isso significa que você deve definir a key mais apropriada para o seu join, baseado no seu conhecimento sobre esses dados, ao invés de procurar por colunas de mesmo nome em ambas as tabelas (WICKHAM; GROLEMUND, 2017). Logo, durante esse processo, nós não estamos perseguindo primary keys de maneira obsessiva, mas sim, pesquisando por relações verdadeiras e lógicas entre as tabelas.
Por exemplo, no caso das tabelas flights e weather, utilizamos as colunas year, month, day, hour e origin como key, pelo fato de que eventos climáticos ocorrem um dado momento (hour) de um dia específico (year, month e day), além de geralmente se restringir a uma dada região geográfica (origin). Curiosamente, essas colunas não foram suficientes para produzirmos uma primary key, mas foram suficientes para representarmos uma conexão lógica entre as tabelas flights e weather.
Assim sendo, qualquer que seja o tipo de key empregado, o processo de join irá ocorrer exatamente da mesma forma. Porém, o tipo que a key assume em cada tabela pode alterar as combinações geradas no resultado do join. Como temos duas tabelas em cada join, temos três possibilidades de relação entre as keys de cada tabela: 1) primary key \(\rightarrow\) primary key; 2) primary key \(\rightarrow\) foreign key; 3) foreign key \(\rightarrow\) foreign key. Ou seja, em cada uma das tabelas envolvidas em um join, as colunas a serem utilizadas como key podem se caracterizar como uma primary key ou como uma foreign key.
Como exemplo, o join formado pelas tabelas info e band_instruments, possui uma relação de primary key \(\rightarrow\) primary key. Pois a coluna name é uma primary key em ambas as tabelas. Por outro lado, o join formado pelas tabelas flights e weather, possui uma relação de foreign key \(\rightarrow\) foreign key, visto que as cinco colunas utilizadas como key não são capazes de identificar unicamente cada observação nas duas tabelas, como comprovamos acima.
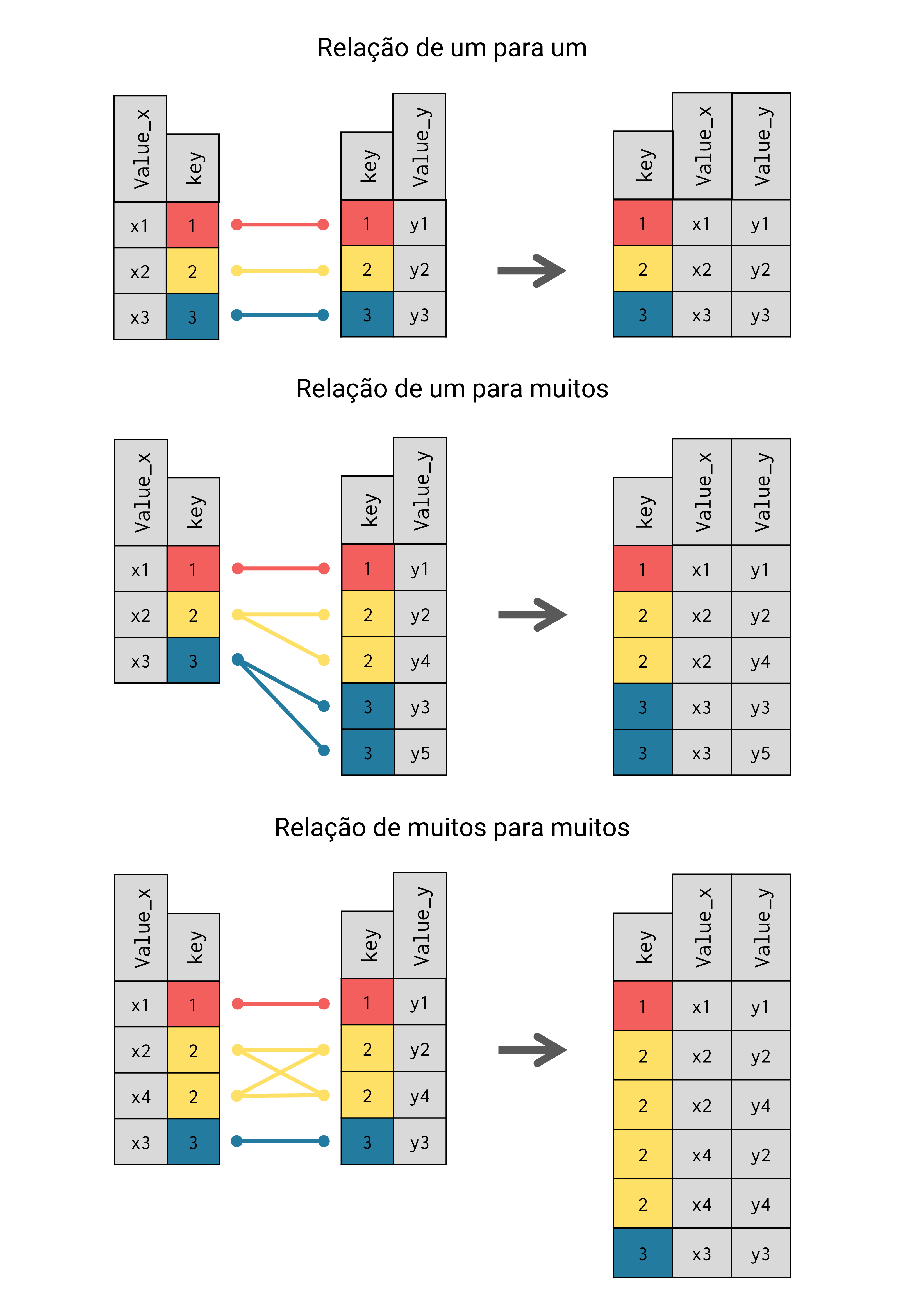
Figura 6.4: Resumo das relações possíveis entre keys, inspirado em Wickham e Grolemund (2017)
Com isso, temos a opção de compreendermos a relação entre as keys, como uma relação de quantidade de cópias, fazendo referência direta ao fato de que uma primary key não possui valores repetidos ao longo da base, enquanto o mesmo não pode ser dito de uma foreign key. Logo, uma relação primary key \(\rightarrow\) primary key pode ser identificada como uma relação de um para um, pois sempre vamos contar com uma única chave para cada observação em ambas as tabelas. Para mais, podemos interpretar uma relação primary key \(\rightarrow\) foreign key, como uma relação de um para muitos, pois para cada chave única presente em uma das tabelas, podemos encontrar múltiplas irmãs gêmeas presentes na outra tabela.
Em contrapartida, se tivermos uma relação foreign key \(\rightarrow\) foreign key, ou uma relação de muitos para muitos, para cada conjunto de keys repetidas em ambas as tabelas, todas as possibilidades de combinação serão geradas. Em outras palavras, nesse tipo de relação, o resultado do join será uma produto cartesiano como demonstrado pela figura 6.4.
Relações de um para um são raras e, por essa razão, você geralmente irá lidar com relações de um para muitos e de muitos para muitos em suas tabelas. No caso de relações de um para muitos, as primary keys são replicadas no resultado do join, para cada repetição de sua key correspondente na outra tabela, como pode ser visto na figura 6.4.
6.7 Portanto, joins podem ser uma fonte de repetições indesejadas em seus dados
Ao explicar as relações de um para muitos e de muitos para muitos entre keys, eu estava querendo destacar que produtos cartesianos são extremamente comuns em todos os tipos de joins. Quando os alunos são introduzidos pela primeira vez ao mundo dos joins, muitos tendem a interpretar que, por exemplo, a função left_join() produz exatamente o mesmo número de linhas que a tabela destinatária (ou a tabela x) utilizada no join. Ou ainda, que se as duas tabelas utilizadas no join possuírem o mesmo número de linhas, que a função inner_join() vai necessariamente retornar um número menor ou igual de linhas em seu resultado.
Essa é uma confusão tão comum, que Hadley Wickham chegou a escrever uma votação no Twitter que demonstra como um produto cartesiano pode ser gerado devido a essa relação entre keys. Como exemplo prático, vamos recriar exatamente a situação que Hadley estava descrevendo nesse tweet. Repare que temos duas tabelas abaixo, df1 e df2. Ambas as tabelas, possuem uma coluna chamada de x. Porém, apenas a tabela df1 possui uma coluna y, e apenas a tabela df2 possui uma coluna z.
df1 <- data.frame(x = c(1, 1), y = c(1, 2))
df2 <- data.frame(x = c(1, 1), z = c(3, 4))
print(df1)## x y
## 1 1 1
## 2 1 2
print(df2)## x z
## 1 1 3
## 2 1 4Ao aplicarmos um inner_join() entre essas tabelas, quantas linhas você espera encontrar no resultado do join? Você provavelmente pensou em 2 linhas, mas na realidade, são retornadas 4 linhas diferentes. Vale destacar que, nessa situação, o resultado de inner_join() é equivalente aos resultados produzidos por full_join(), left_join() e right_join(). Ao observarmos atentamente as combinações entre as colunas y e z, podemos compreender melhor o que está acontecendo neste resultado.
Em ambas as tabelas, a coluna x não é capaz de identificar sozinha cada observação única da tabela, logo, a relação criada pela coluna x é uma relação de muitos para muitos entre as duas tabelas. Por essa razão, o join entre as tabelas df1 e df2 acaba gerando um produto cartesiano entre as duas observações de cada tabela, de modo que, no final, temos \(2 \times 2 = 4\) linhas retornadas. Portanto, todas as combinações possíveis entre \((y, z)\) foram retornadas, sendo elas: \((1,3); (1,4); (2,3); (2,4)\).
inner_join(df1, df2, by = "x")## Warning in inner_join(df1, df2, by = "x"): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 1 of `x` matches multiple rows in `y`.
## ℹ Row 1 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.## x y z
## 1 1 1 3
## 2 1 1 4
## 3 1 2 3
## 4 1 2 4Sendo assim, caso você esteja trabalhando sobre uma tabela A que contém exatas 1000 linhas, e você aplica diversas transformações sobre essa tabela (incluindo a aplicação de joins), e, no final, acaba gerando uma tabela de 1200 linhas, você pode suspeitar que os joins que você está aplicando e os possíveis produtos cartesianos que eles estejam gerando, sejam a fonte de tal expansão de sua tabela.
Em meu trabalho como analista, estou o tempo todo analisando como diversos usuários estão navegando por um determinado fluxo. E para tal análise estou constantemente aplicando joins entre tabelas, e as relações entre as keys dessas tabelas são parte fundamental desse trabalho. Pois caso eu não tenha cuidado com essas relações, eu posso acabar gerando repetições indesejadas de um mesmo usuário, devido ao produto cartesiano gerado no join, e por causa dessas repetições, eu posso acabar interpretando que 100 usuários passaram por um ponto x do fluxo, quando na verdade, apenas 77 usuários de fato passaram por este ponto.
Portanto, quando estiver trabalhando com joins, é importante que você sempre os interprete como uma relação entre os indivíduos ou categorias descritas em cada tabela, e não como um filtro baseado no número de linhas de cada tabela. Um left join não busca gerar um resultado que tem o mesmo número de linhas da tabela destinatária, mas sim, um resultado que contém os mesmos indivíduos ou categorias descritas na tabela destinatária.
6.8 Utilizando joins como a base de um filtro
Durante as seções anteriores mostramos os joins dos tipos inner, full, left e right. Esses tipos de joins são conjuntamente conhecidos como mutating joins, pois eles adicionam novas variáveis a sua tabela (como se fossem uma cópia da função mutate()) baseando-se em um pareamento com as linhas de outra tabela (WICKHAM; GROLEMUND, 2017).
Para além desses tipos de join, temos o conjunto de filtering joins, o qual abarca os anti joins e os semi joins. Para esses dois tipos de joins, o pacote dplyr nos oferece as funções anti_join() e semi_join(). A principal diferença entre os filtering joins e os mutating joins, é que os filtering joins não adicionam novas variáveis à sua tabela, eles apenas filtram as linhas de sua tabela a depender se elas puderam ou não ser encontradas na outra tabela.
Começando pelo anti join, se você possui uma tabela A e uma tabela B, e aplica um anti join sobre essas tabelas, você vai encontrar todas as linhas da tabela A que não foram encontradas na tabela B. Portanto, a função anti_join() é uma forma prática e eficiente de você descobrir quais indivíduos de uma tabela A não são descritos em uma tabela B. Portanto, se voltarmos às tabelas info e band_instruments, perceba abaixo, que apenas as linhas referentes à Mick, George e Ringo são retornadas em um anti join, pois esses músicos da tabela info não estão presentes na tabela band_instruments.
anti_join(
info,
band_instruments,
by = "name"
)## # A tibble: 3 × 4
## name band born children
## <chr> <chr> <date> <lgl>
## 1 Mick Rolling Stones 1943-07-26 TRUE
## 2 George Beatles 1943-02-25 TRUE
## 3 Ringo Beatles 1940-07-07 TRUEPor outro lado, um semi join representa justamente a operação contrária. Isto é, um semi join entre as tabelas A e B, lhe retorna todas as linhas da tabela A que foram encontradas na tabela B. Sendo assim, se aplicarmos a função semi_join() sobre as tabelas info e band_instruments, temos como resultado as linhas referentes aos músicos John e Paul, pelo fato destes músicos estarem presentes em ambas as tabelas.
semi_join(
info,
band_instruments,
by = "name"
)## # A tibble: 2 × 4
## name band born children
## <chr> <chr> <date> <lgl>
## 1 John Beatles 1940-09-10 TRUE
## 2 Paul Beatles 1942-06-18 TRUEExercícios
O primeiro exercício desse capítulo, envolve duas tabelas publicadas na semana 11 do projeto Tidy Tuesday em 2020. Mais especificamente, as tabelas tuition_cost e salary_potential. A tabela tuition_cost descreve os custos de um curso de graduação em diferentes universidades dos EUA. Em contrapartida, a tabela salary_potential fornece uma estimativa do salário pontencial que um diploma de graduação de diversas universidades dos EUA pode fornecer a um profissional.
No Brasil, as faculdades privadas geralmente cobram por uma mensalidade fixa que abrange todos os custos mínimos. Já algumas universidades privadas, tendem a usar um sistema mais complexo, onde uma mensalidade base é cobrada, além de taxas por aulas práticas (para cobrir gastos com o uso de equipamentos) e taxas por matéria matriculada. Em outras palavras, um aluno de uma universidade privada brasileira que se matricula, por exemplo, em 4 matérias num dado semestre, geralmente paga um valor mensal que segue a estrutura: mensalidade base + taxa por aula prática (se houver alguma aula prática) + (4 \(\times\) taxa por matrícula).
Por outro lado, as universidades americanas possuem um sistema mais complexo de cobrança. Primeiro, a maior parte dos estudantes americanos optam por morar e se alimentar nos alojamentos da universidade, ao invés de se manterem na casa dos pais. A universidade cobra uma taxa específica para esses estudantes, que busca pagar justamente os custos deste alojamento e de sua alimentação. Tal custo é geralmente denominado de room and board fees. Segundo, universidades americanas cobram principalmente pelo seu “ensino” (e alguns outros serviços) e, por isso, a maior parte de seus preços envolvem o que chamamos de “tuition fees” (ou “taxa de ensino”). Terceiro, os valores divulgados pelas universidades são geralmente anuais, logo, se o tuition fees (ou room and board fees) de uma universidade qualquer é de $25 mil, isso significa que um curso de 4 anos nessa universidade custaria em torno de $100 mil.
Portanto, as universidades americanas cobram, em geral, dois tipos de custos diferentes (room and board fees e tuition fees) e, esses custos são em sua maioria, anuais. Grande parte dos alunos acabam pagando ambos desses custos, logo, esses custos somados representam, para grande parte da população, o custo total por ano de uma universidade nos EUA.
Para mais, as universidades americanas também cobram taxas de ensino (tuition fees) diferentes de acordo com o estado em que o aluno reside. Ou seja, uma universidade que está sediada no estado do Texas vai cobrar uma taxa mais barata para os alunos que moram no estado do Texas. Porém, os alunos que são originalmente de outros estados, e estão vindo para essa universidade vão pagar taxas maiores.
Questão 6.1. Suponha que você esteja interessado em realizar um curso de graduação em alguma das universidades descritas na tabela tuition_cost. Como você provavelmente não mora nos Estados Unidos, considere os custos referentes a alunos out of state em seus cálculos. Vale também ressaltar que os salários estimados na tabela salary_potential, assim como os custos na tabela tuition_cost, são anuais. Com base nas estimativas de salário presentes na tabela salary_potential e, com base nos custos descritos na tabela tuition_cost, tente calcular (para cada universidade) o tempo de trabalho necessário (após a graduação) para pagar pelo investimento que você aplicou no curso de graduação.
library(tidyverse)
github <- "https://raw.githubusercontent.com/rfordatascience/"
pasta <- "tidytuesday/master/data/2020/2020-03-10/"
cost <- "tuition_cost.csv"
salary <- "salary_potential.csv"
tuition_cost <- read_csv(paste0(github, pasta, cost))
salary_potential <- read_csv(paste0(github, pasta, salary))Questão 6.2. Todos os itens abaixo envolvem as tabelas consumidores e vendedores, alguns itens serão teóricos, outros, vão lhe requisitar o cálculo de alguma informação. Como esses cálculos envolvem as informações de ambas as tabelas, você será obrigado a aplicar um join entre elas para realizá-lo:
library(tidyverse)
github <- "https://raw.githubusercontent.com/pedropark99/"
pasta <- "Curso-R/master/Dados/"
arquivo1 <- "consumidor.csv"
arquivo2 <- "vendedores.csv"
consumidores <- read_csv2(paste0(github, pasta, arquivo1))
vendedores <- read_csv2(paste0(github, pasta, arquivo2))6.2.A) Quais colunas representam as keys em ambas as tabelas?
6.2.B) Na tabela consumidores, quais colunas representam uma primary key, e quais representam uma foreign key?
6.2.C) Descubra o número de cidades nas quais cada vendedor atendeu os seus clientes.
Questão 6.3. Dado que você tenha importado as tabelas filmes e filmes_receita abaixo para o seu R, e, tendo em mente o que vimos nesse capítulo, explique porque o comando de join abaixo não funciona sobre essas tabelas. Dado que você encontre e explique o que está errado, como você ajustaria esse comando para que ele funcione normalmente?
library(tidyverse)
github <- "https://raw.githubusercontent.com/pedropark99/"
pasta <- "Curso-R/master/Dados/"
arquivo1 <- "filmes_dados.csv"
arquivo2<- "filmes_receita.csv"
filmes <- read_csv2(paste0(github, pasta, arquivo1))
filmes_receita <- read_csv2(paste0(github, pasta, arquivo2))
### Porque esse comando de join
### abaixo não funciona?
filmes %>%
left_join(
filmes_receita
)