from pyspark.sql.functions import sum, col
sum_expr = sum(col('Value'))2 Introducing Apache Spark
In essence, pyspark is an API to Apache Spark (or simply Spark). In other words, with pyspark we can build Spark applications using the python language. So, by learning a little more about Spark, you will understand a lot more about pyspark.
2.1 What is Spark?
Spark is a multi-language engine for large-scale data processing that supports both single-node machines and clusters of machines (Apache Spark Official Documentation 2022). Nowadays, Spark became the de facto standard for structure and manage big data applications.
It has a number of features that its predecessors did not have, like the capacity for in-memory processing and stream processing (Karau et al. 2015). But, the most important feature of all, is that Spark is an unified platform for big data processing (Chambers and Zaharia 2018).
This means that Spark comes with multiple built-in libraries and tools that deals with different aspects of the work with big data. It has a built-in SQL engine1 for performing large-scale data processing; a complete library for scalable machine learning (MLib2); a stream processing engine3 for streaming analytics; and much more;
In general, big companies have many different data necessities, and as a result, the engineers and analysts may have to combine and integrate many tools and techniques together, so they can build many different data pipelines to fulfill these necessities. But this approach can create a very serious dependency problem, which imposes a great barrier to support this workflow. This is one of the big reasons why Spark got so successful. It eliminates big part of this problem, by already including almost everything that you might need to use.
Spark is designed to cover a wide range of workloads that previously required separate distributed systems … By supporting these workloads in the same engine, Spark makes it easy and inexpensive to combine different processing types, which is often necessary in production data analysis pipelines. In addition, it reduces the management burden of maintaining separate tools (Karau et al. 2015).
2.2 Spark application
Your personal computer can do a lot of things, but, it cannot efficiently deal with huge amounts of data. For this situation, we need several machines working together, adding up their resources to deal with the volume or complexity of the data. Spark is the framework that coordinates the computations across this set of machines (Chambers and Zaharia 2018). Because of this, a relevant part of Spark’s structure is deeply connected to distributed computing models.
You probably do not have a cluster of machines at home. So, while following the examples in this book, you will be running Spark on a single machine (i.e. single node mode). But lets just forget about this detail for a moment.
In every Spark application, you always have a single machine behaving as the driver node, and multiple machines behaving as the worker nodes. The driver node is responsible for managing the Spark application, i.e. asking for resources, distributing tasks to the workers, collecting and compiling the results, …. The worker nodes are responsible for executing the tasks that are assigned to them, and they need to send the results of these tasks back to the driver node.
Every Spark application is distributed into two different and independent processes: 1) a driver process; 2) and a set of executor processes (Chambers and Zaharia 2018). The driver process, or, the driver program, is where your application starts, and it is executed by the driver node. This driver program is responsible for: 1) maintaining information about your Spark Application; 2) responding to a user’s program or input; 3) and analyzing, distributing, and scheduling work across the executors (Chambers and Zaharia 2018).
Every time a Spark application starts, the driver process has to communicate with the cluster manager, to acquire workers to perform the necessary tasks. In other words, the cluster manager decides if Spark can use some of the resources (i.e. some of the machines) of the cluster. If the cluster manager allow Spark to use the nodes it needs, the driver program will break the application into many small tasks, and will assign these tasks to the worker nodes.
The executor processes, are the processes that take place within each one of the worker nodes. Each executor process is composed of a set of tasks, and the worker node is responsible for performing and executing these tasks that were assigned to him, by the driver program. After executing these tasks, the worker node will send the results back to the driver node (or the driver program). If they need, the worker nodes can communicate with each other, while performing its tasks.
This structure is represented in Figure 2.1:
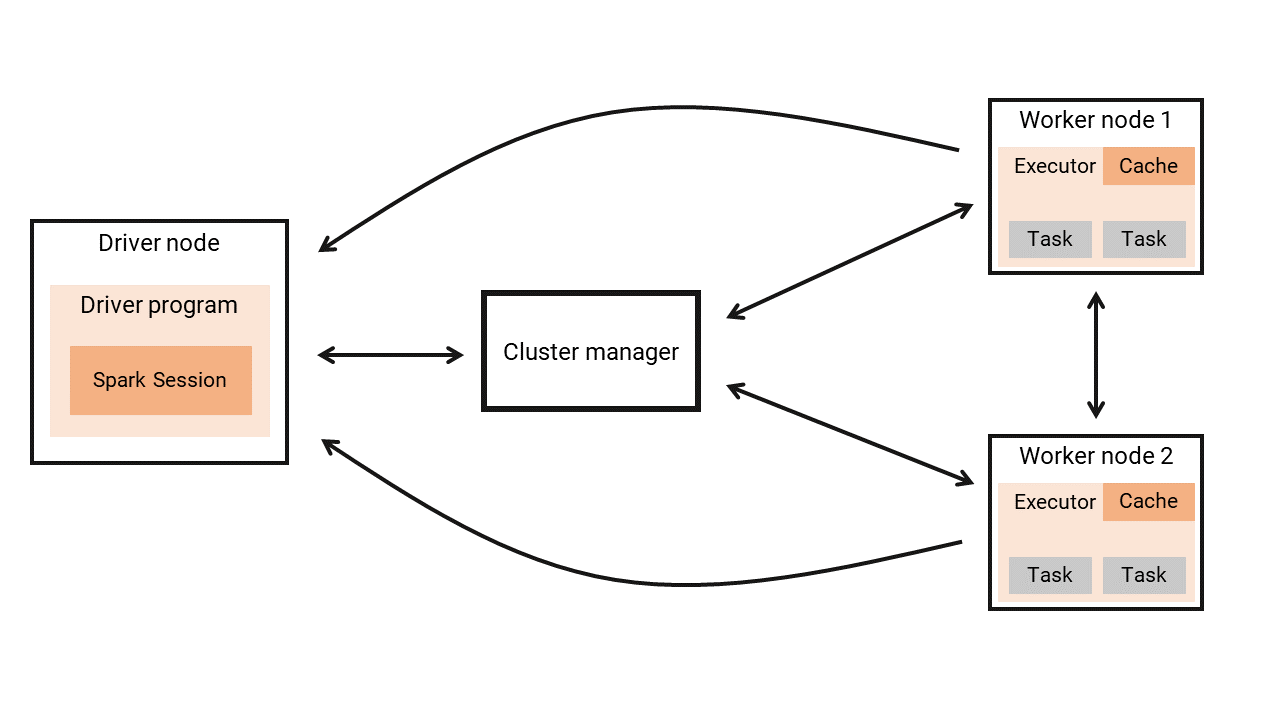
When you run Spark on a cluster of computers, you write the code of your Spark application (i.e. your pyspark code) on your (single) local computer, and then, submit this code to the driver node. After that, the driver node takes care of the rest, by starting your application, creating your Spark Session, asking for new worker nodes, sending the tasks to be performed, collecting and compiling the results and giving back these results to you.
However, when you run Spark on your (single) local computer, the process is very similar. But, instead of submitting your code to another computer (which is the driver node), you will submit to your own local computer. In other words, when Spark is running on single-node mode, your computer becomes the driver and the worker node at the same time.
2.3 Spark application versus pyspark application
The pyspark package is just a tool to write Spark applications using the python programming language. This means, that every pyspark application is a Spark application written in python.
With this conception in mind, you can understand that a pyspark application is a description of a Spark application. When we compile (or execute) our python program, this description is translated into a raw Spark application that will be executed by Spark.
To write a pyspark application, you write a python script that uses the pyspark library. When you execute this python script with the python interpreter, the application will be automatically converted to Spark code, and will be sent to Spark to be executed across the cluster;
2.4 Core parts of a pyspark program
In this section, I want to point out the core parts that composes every pyspark program. This means that every pyspark program that you write will have these “core parts”, which are:
importing the
pysparkpackage (or modules);starting your Spark Session;
defining a set of transformations and actions over Spark DataFrames;
2.4.1 Importing the pyspark package (or modules)
Spark comes with a lot of functionality installed. But, in order to use it in your pyspark program, you have to import most of these functionalities to your session. This means that you have to import specific packages (or “modules”) of pyspark to your python session.
For example, most of the functions used to define our transformations and aggregations in Spark DataFrames, comes from the pyspark.sql.functions module.
That is why we usually start our python scripts by importing functions from this module, like this:
Or, importing the entire module with the import keyword, like this:
import pyspark.sql.functions as F
sum_expr = F.sum(F.col('Value'))2.4.2 Starting your Spark Session
Every Spark application starts with a Spark Session. Basically, the Spark Session is the entry point to your application. This means that, in every pyspark program that you write, you should always start by defining your Spark Session. We do this, by using the getOrCreate() method from pyspark.sql.SparkSession.builder module.
Just store the result of this method in any python object. Is very common to name this object as spark, like in the example below. This way, you can access all the information and methods of Spark from this spark object.
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2.4.3 Defining a set of transformations and actions
Every pyspark program is composed by a set of transformations and actions over a set of Spark DataFrames.
I will explain Spark DataFrames in more deth on the Chapter 3. For now just understand that they are the basic data sctructure that feed all pyspark programs. In other words, on every pyspark program we are transforming multiple Spark DataFrames to get the result we want.
As an example, in the script below we begin with the Spark DataFrame stored in the object students, and, apply multiple transformations over it to build the ar_department DataFrame. Lastly, we apply the .show() action over the ar_department DataFrame:
from pyspark.sql.functions import col
# Apply some transformations over
# the `students` DataFrame:
ar_department = students\
.filter(col('Age') > 22)\
.withColumn('IsArDepartment', col('Department') == 'AR')\
.orderBy(col('Age').desc())
# Apply the `.show()` action
# over the `ar_department` DataFrame:
ar_department.show()2.5 Building your first Spark application
To demonstrate what a pyspark program looks like, lets write and run our first example of a Spark application. This Spark application will build a simple table of 1 column that contains 5 numbers, and then, it will return a simple python list containing this five numbers as a result.
2.5.1 Writing the code
First, create a new blank text file in your computer, and save it somewhere with the name spark-example.py. Do not forget to put the .py extension in the name. This program we are writing together is a python program, and should be treated as such. With the .py extension in the name file, you are stating this fact quite clearly to your computer.
After you created and saved the python script (i.e. the text file with the .py extension), you can start writing your pyspark program. As we noted in the previous section, you should always start your pyspark program by defining your Spark Session, with this code:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()After you defined your Spark Session, and saved it in an object called spark, you can now access all Spark’s functionality through this spark object.
To create our first Spark table we use the range() method from the spark object. The range() method works similarly as the standard python function called range(). It basically creates a sequence of numbers, from 0 to \(n - 1\). However, this range() method from spark stores this sequence of numbers as rows in a Spark table (or a Spark DataFrame):
table = spark.range(5)After this step, we want to collect all the rows of the resulting table into a python list. And to do that, we use the collect() method from the Spark table:
result = table.collect()
print(result)So, the entire program is composed of these three parts (or sections) of code. If you need it, the entire program is reproduced below. You can copy and paste all of this code to your python script, and then, save it:
# The entire program:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
table = spark.range(5)
result = table.collect()
print(result)2.5.2 Executing the code
Now that you have written your first Spark application with pyspark, you want to execute this application and see its results. Yet, to run a pyspark program, remember that you need to have the necessary software installed on your machine. In case you do not have Apache Spark installed yet, I personally recommend you to read the articles from PhoenixNAP on how to install Apache Spark4.
Anyway, to execute this pyspark that you wrote, you need send this script to the python interpreter, and to do this you need to: 1) open a terminal inside the folder where you python script is stored; and, 2) use the python command from the terminal with the name of your python script.
In my current situation, I running Spark on a Ubuntu distribution, and, I saved the spark-example.py script inside a folder called SparkExample. This means that, I need to open a terminal that is rooted inside this SparkExample folder.
You probably have saved your spark-example.py file in a different folder of your computer. This means that you need to open the terminal from a different folder.
After I opened a terminal rooted inside the SparkExample folder. I just use the python3 command to access the python interpreter, and, give the name of the python script that I want to execute. In this case, the spark-example.py file. As a result, our first pyspark program will be executed:
Terminal$ python3 spark-example.py[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4)]You can see in the above result, that this Spark application produces a sequence of Row objects, inside a Python list. Each row object contains a number from 0 to 4.
Congratulations! You have just run your first Spark application using pyspark!
2.6 Overview of pyspark
Before we continue, I want to give you a very brief overview of the main parts of pyspark that are the most useful and most important to know of.
2.6.1 Main python modules
The main python modules that exists in pyspark are:
pyspark.sql.SparkSession: theSparkSessionclass that defines your Spark Session, or, the entry point to your Spark application;pyspark.sql.dataframe: module that defines theDataFrameclass;pyspark.sql.column: module that defines theColumnclass;pyspark.sql.types: module that contains all data types of Spark;pyspark.sql.functions: module that contains all of the main Spark functions that we use in transformations;pyspark.sql.window: module that defines theWindowclass, which is responsible for defining windows in a Spark DataFrame;
2.6.2 Main python classes
The main python classes that exists in pyspark are:
DataFrame: represents a Spark DataFrame, and it is the main data structure inpyspark. In essence, they represent a collection of datasets into named columns;Column: represents a column in a Spark DataFrame;GroupedData: represents a grouped Spark DataFrame (result ofDataFrame.groupby());Window: describes a window in a Spark DataFrame;DataFrameReaderandDataFrameWriter: classes responsible for reading data from a data source into a Spark DataFrame, and writing data from a Spark DataFrame into a data source;DataFrameNaFunctions: class that stores all main methods for dealing with null values (i.e. missing data);