1. Introduction
You might have some Figma files that you want to bring into R, to analyze, or, use the visual attributes of the objects from this file to compose a layout that you want to use in a RMarkdown/Quarto file.
The figma package allows you to that. It uses the Figma
API to bring all of your Figma file data into R. It does this, by
sending a HTTP request to the Figma API to collect all of your Figma
data, and then, it parses this data into a R native object, so you can
easily use it in your R process.
But in order to use the Figma API, you need to collect two key variables about your file and your credentials. They are:
-
file_key: The ID (or the “key”) that identifies your Figma file; -
token: Your personal access token from the Figma platform;
However, if you want to use get_figma_page(), you will
need to collect a third information, which is the node_id,
or the ID that identifies a canvas/page of your Figma file. We will talk
about this ID on section 1.2.
1.1 Is always nice to read the official Figma API documentation
Some of the information described in this vignette comes from the official Figma API documentation, and in order to learn more about a specific subject, is always a good idea to read about that subject directly from the source 😉.
I will give you direct links to specific parts of the documentation throughout this vignette, but if you want to read the complete documentation, you can access this link.
1.2 Finding the key (or ID) of your Figma file
The file key (or the file key), is a random text that identifies your Figma file. The Figma API uses this key to identify which specific Figma file you are requesting for.
You can find the key (or ID) of your Figma file by looking at the URL
in your web browser, when you access your Figma file at the Figma
platform. As an example, lets use this Figma file entitled
Untitled (I will not make a joke on that 😅):
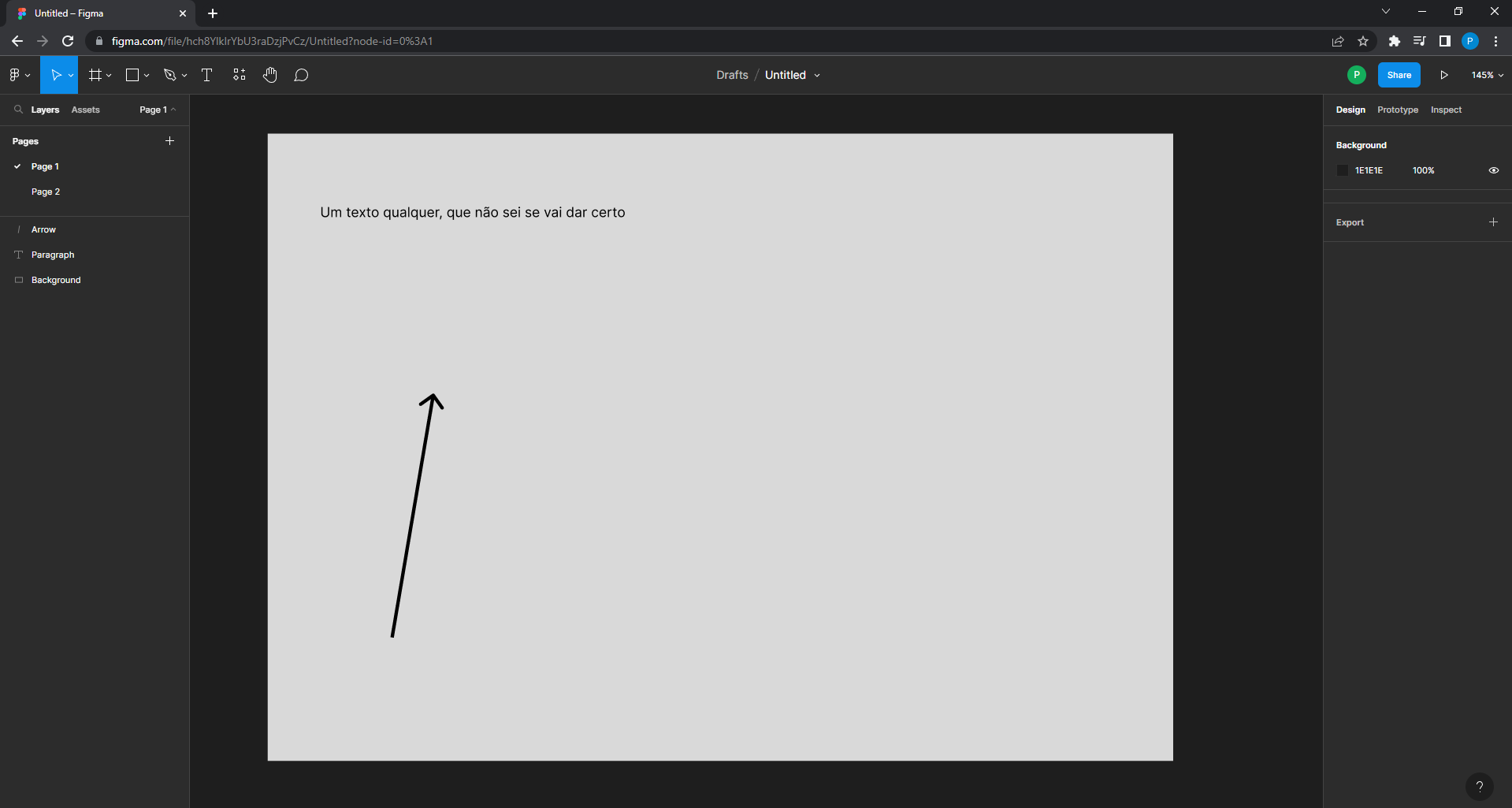
An example of Figma file
If we look at the top of my web browser, we have the following URL:
https://www.figma.com/file/hch8YlkIrYbU3raDzjPvCz/Untitled?node-id=0%3A1
The key (or the ID) of this file is
"hch8YlkIrYbU3raDzjPvCz". This means that the URL of every
Figma file is composed of this structure. So in order to use the
functions from the figma package, you should always collect
this :file_key portion of the URL, to get the key to your
file.
https://www.figma.com/file/:file_key/:file_title?:node_id
This also means that, if you want to use
get_figma_page(), you will need to collect the
:node_id portion of the URL as well. This portion gives you
the node ID, or, in other words, the ID that identifies the canvas/page
you are on. This portion of the URL is usually a key-value pair, where
the ID of your node is after the equal sign (=).
For example, by looking at the URL example that we gave above, we
know that the canvas/page where I am is the page of
node_id = "0%3A1".
1.3 Get your personal access token
You can read more about the authentication process and the use of
personal access tokens, in the section
“Authentication” of the Figma API documentation. If you do not have
a personal access token, you can create one in the Figma platform. Just
log in the platform, and click on the Settings section,
like in the image below:
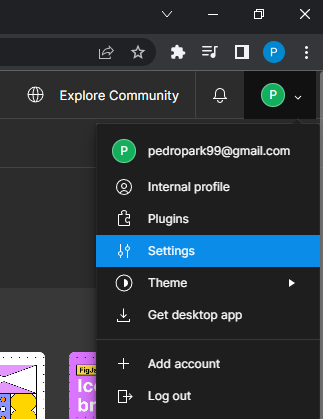
Settings of Figma platform
After that, look for the Personal access token section
of the settings, like in the image below. This is where you can create
all of your personal access tokens. Just add a description (or a
“alias”) to your token, and press Enter. A pop-up should appear in your
screen with your new token.
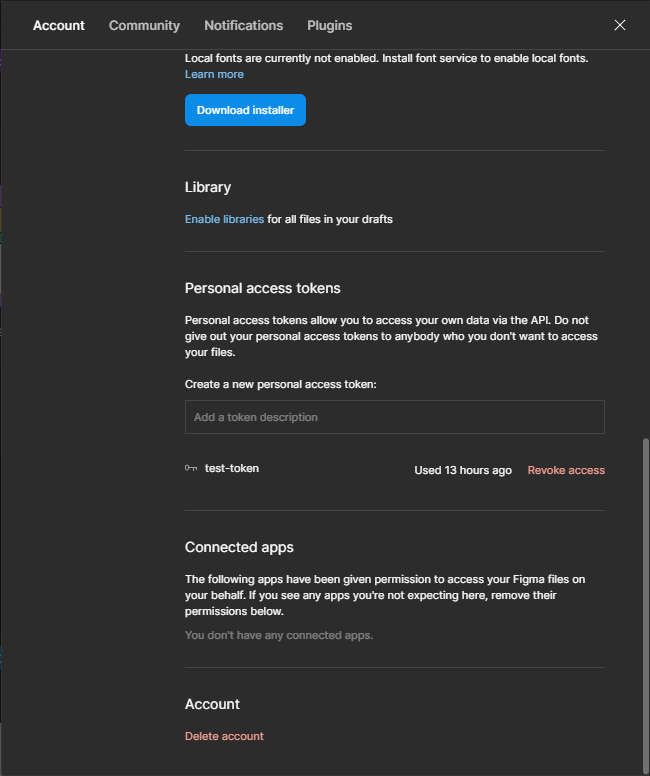
Personal access token section in settings
The Figma API uses this secret token to identify you, to know that is you that is requesting for a file, and not someone else. Because of this, is important to keep this token a secret, because if someone have it, they can access your Figma files through the API.
A standard way to store these passwords, is to store them in the
.Renviron file, but there are many other methods that are
good alternatives too. A good place to start is the vignette
from Hadley Wickham.
1.4 Use get_figma_file() to get your Figma file
Now that you have the key (or ID) that identifies your Figma file,
and your personal token that identifies yourself, you can use
get_figma_file() to get your Figma file:
file_key <- "hch8YlkIrYbU3raDzjPvCz"
# Insert your personal token:
token <- "Your personal token ..."
result <- figma::get_figma_file(
file_key, token
)
# A `response` object:
print(result)Response [https://api.figma.com/v1/files/hch8YlkIrYbU3raDzjPvCz]
Date: 2022-10-29 16:56
Status: 200
Content-Type: application/json; charset=utf-8
Size: 4.58 kB
{"document":{"id":"0:0","name":"Document","type":"DOCUMENT","children":[{"id":"0:1","name":"Page 1","typ...1.5 Using the response object
The functions from figma package have the philosophy of
giving (by default) the most raw and unprocessed result as possible to
the user. This is good for debugging situations, because it gives all
the available information to the user.
However, this unprocessed result is usually not strucutured in a very
friendly and useful format, which makes analysis and transformation
pipelines harder and more complex. That is why
get_figma_file() comes with more output formats available
through the .output_format argument, which we will describe
later.
To give you an useful example, you can access the exact
response object shown in the example of section 1.4. This
response object is stored in a data object called
untitled_file, that you can access with
data("untitled_file", package = "figma"). This object
untitled_file contains all of the data from the Figma file
shown in section 1.2.
As you can see in the result below, a response object is
just a simple R list with many elements:
str(untitled_file)
#> List of 10
#> $ url : chr "https://api.figma.com/v1/files/hch8YlkIrYbU3raDzjPvCz"
#> $ status_code: int 200
#> $ headers :List of 12
#> ..$ content-type : chr "application/json; charset=utf-8"
#> ..$ date : chr "Sat, 29 Oct 2022 16:56:50 GMT"
#> ..$ access-control-allow-origin : chr "*"
#> ..$ access-control-allow-headers: chr "Content-Type, X-Figma-Token, Authorization"
#> ..$ cache-control : chr "no-cache, no-store"
#> ..$ vary : chr "X-Figma-Token,Authorization"
#> ..$ x-cache : chr "Miss from cloudfront"
#> ..$ via : chr "1.1 88c333921d5c405e037b84bb8c2dc33e.cloudfront.net (CloudFront)"
#> ..$ x-amz-cf-pop : chr "GRU3-P1"
#> ..$ alt-svc : chr "h3=\":443\"; ma=86400"
#> ..$ x-amz-cf-id : chr "gjOnBhIpDZxekWpx-zbAwqxsOLunePv8LSTfdf-elMQNLXpyAVSuXw=="
#> ..$ strict-transport-security : chr "max-age=31536000; includeSubDomains; preload"
#> ..- attr(*, "class")= chr [1:2] "insensitive" "list"
#> $ all_headers:List of 1
#> ..$ :List of 3
#> .. ..$ status : int 200
#> .. ..$ version: chr "HTTP/2"
#> .. ..$ headers:List of 12
#> .. .. ..$ content-type : chr "application/json; charset=utf-8"
#> .. .. ..$ date : chr "Sat, 29 Oct 2022 16:56:50 GMT"
#> .. .. ..$ access-control-allow-origin : chr "*"
#> .. .. ..$ access-control-allow-headers: chr "Content-Type, X-Figma-Token, Authorization"
#> .. .. ..$ cache-control : chr "no-cache, no-store"
#> .. .. ..$ vary : chr "X-Figma-Token,Authorization"
#> .. .. ..$ x-cache : chr "Miss from cloudfront"
#> .. .. ..$ via : chr "1.1 88c333921d5c405e037b84bb8c2dc33e.cloudfront.net (CloudFront)"
#> .. .. ..$ x-amz-cf-pop : chr "GRU3-P1"
#> .. .. ..$ alt-svc : chr "h3=\":443\"; ma=86400"
#> .. .. ..$ x-amz-cf-id : chr "gjOnBhIpDZxekWpx-zbAwqxsOLunePv8LSTfdf-elMQNLXpyAVSuXw=="
#> .. .. ..$ strict-transport-security : chr "max-age=31536000; includeSubDomains; preload"
#> .. .. ..- attr(*, "class")= chr [1:2] "insensitive" "list"
#> $ cookies :'data.frame': 0 obs. of 7 variables:
#> ..$ domain : logi(0)
#> ..$ flag : logi(0)
#> ..$ path : logi(0)
#> ..$ secure : logi(0)
#> ..$ expiration: 'POSIXct' num(0)
#> ..$ name : logi(0)
#> ..$ value : logi(0)
#> $ content : raw [1:4582] 7b 22 64 6f ...
#> $ date : POSIXct[1:1], format: "2022-10-29 16:56:50"
#> $ times : Named num [1:6] 0 0.173 0.275 0.378 1.606 ...
#> ..- attr(*, "names")= chr [1:6] "redirect" "namelookup" "connect" "pretransfer" ...
#> $ request :List of 5
#> ..$ method : chr "GET"
#> ..$ url : chr "https://api.figma.com/v1/files/hch8YlkIrYbU3raDzjPvCz"
#> ..$ fields : NULL
#> ..$ options:List of 2
#> .. ..$ useragent: chr "libcurl/7.68.0 r-curl/4.3.2 httr/1.4.3"
#> .. ..$ httpget : logi TRUE
#> ..$ output : list()
#> .. ..- attr(*, "class")= chr [1:2] "write_memory" "write_function"
#> ..- attr(*, "class")= chr "request"
#> $ handle :Class 'curl_handle' <externalptr>
#> - attr(*, "class")= chr "response"All of your Figma file data is in the content element,
so, you would use the command untitled_file$content to
access it. But, by default, the Figma API sends the data of your Figma
file as raw bytes:
head(untitled_file$content)
#> [1] 7b 22 64 6f 63 75So you need to convert these bytes in a more useful format like a
JSON object, or a character vector, or as pure text. To do this
conversion, I recommend you to use the httr::content()
function. By default, this function converts the raw bytes into a R
list.
list_of_nodes <- httr::content(untitled_file)
names(list_of_nodes)
#> [1] "document" "components" "componentSets" "schemaVersion"
#> [5] "styles" "name" "lastModified" "thumbnailUrl"
#> [9] "version" "role" "editorType" "linkAccess"The canvas/pages nodes are in the
list_of_nodes$document$children element, and the objects
nodes are in the children element of each canvas/page node
(e.g.
list_of_nodes$document$children[[1]][["children"]]).
first_canvas_node <- list_of_nodes$document$children[[1]]
first_object_node <- first_canvas_node[["children"]][[1]]1.6 Output a Figma Document object
With .output_argument = "figma_document",
get_figma_file() will output a Figma Document object,
instead of a response object.
file_key <- "hch8YlkIrYbU3raDzjPvCz"
# Insert your personal token:
token <- "Your personal token ..."
figma_document <- figma::get_figma_file(
file_key, token,
.output_format = "figma_document"
)
# A `figma_document` object:
print(figma_document)Or, analogously:
figma_document <- figma::as_figma_document(untitled_file)
figma_document
#> <Figma Document>
#>
#> * Number of canvas: 2
#> * Number of objects in each canvas: 3 2This object is just a R list with class figma_document.
The main differences between this object and the response
object are:
- the
figma_documentobject have only data about your Figma file (i.e. no data about the HTTP request made to the Figma API); - the data of your Figma file is a little more organized in the
figma_documentobject;
In a figma_document object, all of the document metadata
of your Figma file (like the name/title of the file, the last time it
was modified, its components, etc…) is available in the
document element:
str(figma_document$document)
#> List of 13
#> $ id : chr "0:0"
#> $ type : chr "DOCUMENT"
#> $ name : chr "Untitled"
#> $ components : Named list()
#> $ componentSets: Named list()
#> $ styles : Named list()
#> $ schemaVersion: int 0
#> $ lastModified : chr "2022-10-25T00:36:59Z"
#> $ thumbnailUrl : chr "https://s3-alpha-sig.figma.com/thumbnails/065f8c7c-af9c-4f7f-bb80-e1c9ad6b62b5?Expires=1667779200&Signature=Gz5"| __truncated__
#> $ version : chr "2514657369"
#> $ role : chr "owner"
#> $ editorType : chr "figma"
#> $ linkAccess : chr "view"Furthermore, you can get the data of each canvas/page (and their
respective objects) in the canvas element:
names(figma_document$canvas[[1]])
#> [1] "id" "name" "type"
#> [4] "objects" "backgroundColor" "prototypeStartNodeID"
#> [7] "flowStartingPoints" "prototypeDevice"And the data of all the objects present in each canvas is found in
the objects element:
first_canvas_node <- figma_document$canvas[[1]]
first_object_node <- first_canvas_node$objects[[1]]
str(first_object_node)
#> List of 12
#> $ id : chr "1:2"
#> $ name : chr "Background"
#> $ type : chr "RECTANGLE"
#> $ blendMode : chr "PASS_THROUGH"
#> $ absoluteBoundingBox :List of 4
#> ..$ x : num -379
#> ..$ y : num -277
#> ..$ width : num 793
#> ..$ height: num 549
#> $ absoluteRenderBounds:List of 4
#> ..$ x : num -379
#> ..$ y : num -277
#> ..$ width : num 793
#> ..$ height: num 549
#> $ constraints :List of 2
#> ..$ vertical : chr "TOP"
#> ..$ horizontal: chr "LEFT"
#> $ fills :List of 1
#> ..$ :List of 3
#> .. ..$ blendMode: chr "NORMAL"
#> .. ..$ type : chr "SOLID"
#> .. ..$ color :List of 4
#> .. .. ..$ r: num 0.851
#> .. .. ..$ g: num 0.851
#> .. .. ..$ b: num 0.851
#> .. .. ..$ a: num 1
#> $ strokes : list()
#> $ strokeWeight : num 1
#> $ strokeAlign : chr "INSIDE"
#> $ effects : list()1.7 Output a tibble::tibble() object
With .output_format = "tibble,
get_figma_file() will output a
tibble::tibble() object, instead of a response
object. This is probably the most useful and friendly output format that
you can use:
file_key <- "hch8YlkIrYbU3raDzjPvCz"
# Insert your personal token:
token <- "Your personal token ..."
tibble <- figma::get_figma_file(
file_key, token,
.output_format = "tibble"
)
# A `tibble` object:
print(tibble)Or, analogously:
tibble <- figma::as_tibble(untitled_file)
tibble
#> # A tibble: 5 × 7
#> canvas_id canvas_name canvas_type object_id object_name objec…¹ object_attrs
#> <chr> <chr> <chr> <chr> <chr> <chr> <list>
#> 1 0:1 Page 1 CANVAS 1:2 Background RECTAN… <named list>
#> 2 0:1 Page 1 CANVAS 5:2 Paragraph TEXT <named list>
#> 3 0:1 Page 1 CANVAS 5:3 Arrow VECTOR <named list>
#> 4 5:4 Page 2 CANVAS 5:5 BackgroundPa… RECTAN… <named list>
#> 5 5:4 Page 2 CANVAS 5:6 Texto da pág… TEXT <named list>
#> # … with abbreviated variable name ¹object_typeEach row in the resulting tibble, is a object present in one of the
canvas of your Figma file. As an example, the Figma file stored in
untitled_file have 2 canvas/pages: 3 objects in the first
canvas, and 2 objects in the second canvas. So 3 objects + 2 objects = 5
rows in the output tibble.
The columns with canvas_ prefix stores the metadata
about the canvas on which the object of the corresponding row is. And
the columns with object_ prefix stores the data about the
object of the corresponding row.
Each object can have a different type (it can be a RECTANGLE, a TEXT,
a VECTOR, etc.), and different types of objects usually have different
kinds of attributes. The attributes of each object are stored in the
object_attributes column.